A Generative Adversarial Network, or GAN, is a type of neural network architecture for generative modeling.
Generative modeling involves using a model to generate new examples that plausibly come from an existing distribution of samples, such as generating new photographs that are similar but specifically different from a dataset of existing photographs.
A GAN is a generative model that is trained using two neural network models. One model is called the “generator” or “generative network” model that learns to generate new plausible samples. The other model is called the “discriminator” or “discriminative network” and learns to differentiate generated examples from real examples.
The two models are set up in a contest or a game (in a game theory sense) where the generator model seeks to fool the discriminator model, and the discriminator is provided with both examples of real and generated samples.
After training, the generative model can then be used to create new plausible samples on demand.
GANs have very specific use cases and it can be difficult to understand these use cases when getting started.
In this post, we will review a large number of interesting applications of GANs to help you develop an intuition for the types of problems where GANs can be used and useful. It’s not an exhaustive list, but it does contain many example uses of GANs that have been in the media.
We will divide these applications into the following areas:
- Generate Examples for Image Datasets
- Generate Photographs of Human Faces
- Generate Realistic Photographs
- Generate Cartoon Characters
- Image-to-Image Translation
- Text-to-Image Translation
- Semantic-Image-to-Photo Translation
- Face Frontal View Generation
- Generate New Human Poses
- Photos to Emojis
- Photograph Editing
- Face Aging
- Photo Blending
- Super Resolution
- Photo Inpainting
- Clothing Translation
- Video Prediction
- 3D Object Generation
Did I miss an interesting application of GANs or great paper on a specific GAN application?
Please let me know in the comments.
Generate Examples for Image Datasets
Generating new plausible samples was the application described in the original paper by Ian Goodfellow, et al. in the 2014 paper “Generative Adversarial Networks” where GANs were used to generate new plausible examples for the MNIST handwritten digit dataset, the CIFAR-10 small object photograph dataset, and the Toronto Face Database.

Examples of GANs used to Generate New Plausible Examples for Image Datasets.Taken from Generative Adversarial Nets, 2014.
This was also the demonstration used in the important 2015 paper titled “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks” by Alec Radford, et al. called DCGAN that demonstrated how to train stable GANs at scale. They demonstrated models for generating new examples of bedrooms.

Example of GAN-Generated Photographs of Bedrooms.Taken from Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Importantly, in this paper, they also demonstrated the ability to perform vector arithmetic with the input to the GANs (in the latent space) both with generated bedrooms and with generated faces.
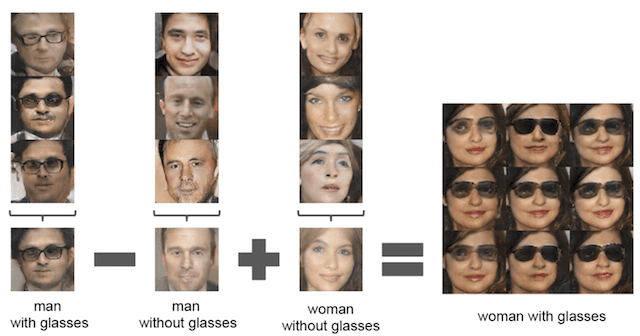
Example of Vector Arithmetic for GAN-Generated Faces.Taken from Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks, 2015.
Generate Photographs of Human Faces
Tero Karras, et al. in their 2017 paper titled “Progressive Growing of GANs for Improved Quality, Stability, and Variation” demonstrate the generation of plausible realistic photographs of human faces. They are so real looking, in fact, that it is fair to call the result remarkable. As such, the results received a lot of media attention. The face generations were trained on celebrity examples, meaning that there are elements of existing celebrities in the generated faces, making them seem familiar, but not quite.

Examples of Photorealistic GAN-Generated Faces.Taken from Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Their methods were also used to demonstrate the generation of objects and scenes.

Example of Photorealistic GAN-Generated Objects and ScenesTaken from Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
Examples from this paper were used in a 2018 report titled “The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation” to demonstrate the rapid progress of GANs from 2014 to 2017 (found via this tweet by Ian Goodfellow).

Example of the Progression in the Capabilities of GANs from 2014 to 2017.Taken from The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation, 2018.
Generate Realistic Photographs
Andrew Brock, et al. in their 2018 paper titled “Large Scale GAN Training for High Fidelity Natural Image Synthesis” demonstrate the generation of synthetic photographs with their technique BigGAN that are practically indistinguishable from real photographs.

Example of Realistic Synthetic Photographs Generated with BigGANTaken from Large Scale GAN Training for High Fidelity Natural Image Synthesis, 2018.
Generate Cartoon Characters
Yanghua Jin, et al. in their 2017 paper titled “Towards the Automatic Anime Characters Creation with Generative Adversarial Networks” demonstrate the training and use of a GAN for generating faces of anime characters (i.e. Japanese comic book characters).

Example of GAN-Generated Anime Character Faces.Taken from Towards the Automatic Anime Characters Creation with Generative Adversarial Networks, 2017.
Inspired by the anime examples, a number of people have tried to generate Pokemon characters, such as the pokeGAN project and the Generate Pokemon with DCGAN project, with limited success.

Example of GAN-Generated Pokemon Characters.Taken from the pokeGAN project.
Image-to-Image Translation
This is a bit of a catch-all task, for those papers that present GANs that can do many image translation tasks.
Phillip Isola, et al. in their 2016 paper titled “Image-to-Image Translation with Conditional Adversarial Networks” demonstrate GANs, specifically their pix2pix approach for many image-to-image translation tasks.
Examples include translation tasks such as:
- Translation of semantic images to photographs of cityscapes and buildings.
- Translation of satellite photographs to Google Maps.
- Translation of photos from day to night.
- Translation of black and white photographs to color.
- Translation of sketches to color photographs.

Example of Photographs of Daytime Cityscapes to Nighttime With pix2pix.Taken from Image-to-Image Translation with Conditional Adversarial Networks, 2016.

Example of Sketches to Color Photographs With pix2pix.Taken from Image-to-Image Translation with Conditional Adversarial Networks, 2016.
Jun-Yan Zhu in their 2017 paper titled “Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks” introduce their famous CycleGAN and a suite of very impressive image-to-image translation examples.
The example below demonstrates four image translation cases:
- Translation from photograph to artistic painting style.
- Translation of horse to zebra.
- Translation of photograph from summer to winter.
- Translation of satellite photograph to Google Maps view.

Example of Four Image-to-Image Translations Performed With CycleGANTaken from Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
The paper also provides many other examples, such as:
- Translation of painting to photograph.
- Translation of sketch to photograph.
- Translation of apples to oranges.
- Translation of photograph to artistic painting.

Example of Translation from Paintings to Photographs With CycleGAN.Taken from Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, 2017.
Text-to-Image Translation (text2image)
Han Zhang, et al. in their 2016 paper titled “StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks” demonstrate the use of GANs, specifically their StackGAN to generate realistic looking photographs from textual descriptions of simple objects like birds and flowers.

Example of Textual Descriptions and GAN-Generated Photographs of BirdsTaken from StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks, 2016.
Scott Reed, et al. in their 2016 paper titled “Generative Adversarial Text to Image Synthesis” also provide an early example of text to image generation of small objects and scenes including birds, flowers, and more.

Example of Textual Descriptions and GAN-Generated Photographs of Birds and Flowers.Taken from Generative Adversarial Text to Image Synthesis.
Ayushman Dash, et al. provide more examples on seemingly the same dataset in their 2017 paper titled “TAC-GAN – Text Conditioned Auxiliary Classifier Generative Adversarial Network“.
Scott Reed, et al. in their 2016 paper titled “Learning What and Where to Draw” expand upon this capability and use GANs to both generate images from text and use bounding boxes and key points as hints as to where to draw a described object, like a bird.
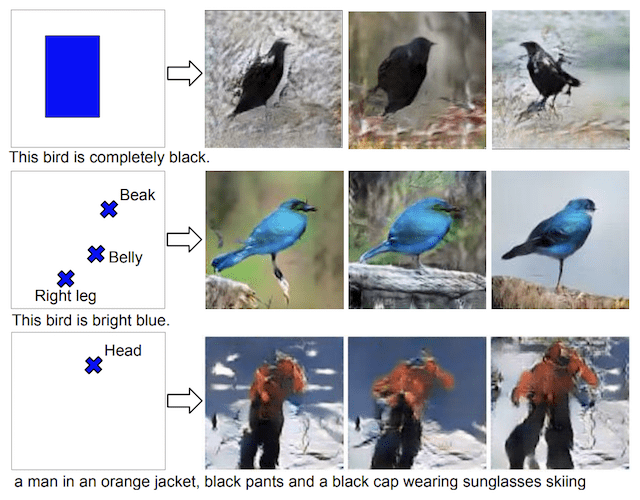
Example of Photos of Object Generated From Text and Position Hints With a GAN.Taken from Learning What and Where to Draw, 2016.
Semantic-Image-to-Photo Translation
Ting-Chun Wang, et al. in their 2017 paper titled “High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs” demonstrate the use of conditional GANs to generate photorealistic images given a semantic image or sketch as input.

Example of Semantic Image and GAN-Generated Cityscape Photograph.Taken from High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs, 2017.
Specific examples included:
- Cityscape photograph, given semantic image.
- Bedroom photograph, given semantic image.
- Human face photograph, given semantic image.
- Human face photograph, given sketch.
They also demonstrate an interactive editor for manipulating the generated image.
Face Frontal View Generation
Rui Huang, et al. in their 2017 paper titled “Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis” demonstrate the use of GANs for generating frontal-view (i.e. face on) photographs of human faces given photographs taken at an angle. The idea is that the generated front-on photos can then be used as input to a face verification or face identification system.

Example of GAN-based Face Frontal View Photo GenerationTaken from Beyond Face Rotation: Global and Local Perception GAN for Photorealistic and Identity Preserving Frontal View Synthesis, 2017.
Generate New Human Poses
Liqian Ma, et al. in their 2017 paper titled “Pose Guided Person Image Generation” provide an example of generating new photographs of human models with new poses.

Example of GAN-Generated Photographs of Human PosesTaken from Pose Guided Person Image Generation, 2017.
Photos to Emojis
Yaniv Taigman, et al. in their 2016 paper titled “Unsupervised Cross-Domain Image Generation” used a GAN to translate images from one domain to another, including from street numbers to MNIST handwritten digits, and from photographs of celebrities to what they call emojis or small cartoon faces.

Example of Celebrity Photographs and GAN-Generated Emojis.Taken from Unsupervised Cross-Domain Image Generation, 2016.
Photograph Editing
Guim Perarnau, et al. in their 2016 paper titled “Invertible Conditional GANs For Image Editing” use a GAN, specifically their IcGAN, to reconstruct photographs of faces with specific specified features, such as changes in hair color, style, facial expression, and even gender.
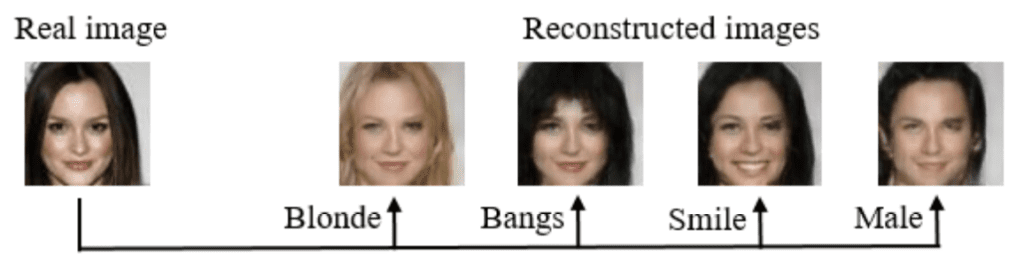
Example of Face Photo Editing with IcGAN.Taken from Invertible Conditional GANs For Image Editing, 2016.
Ming-Yu Liu, et al. in their 2016 paper titled “Coupled Generative Adversarial Networks” also explore the generation of faces with specific properties such as hair color, facial expression, and glasses. They also explore the generation of other images, such as scenes with varied color and depth.

Example of GANs used to Generate Faces With and Without Blond Hair.Taken from Coupled Generative Adversarial Networks, 2016.
Andrew Brock, et al. in their 2016 paper titled “Neural Photo Editing with Introspective Adversarial Networks” present a face photo editor using a hybrid of variational autoencoders and GANs. The editor allows rapid realistic modification of human faces including changing hair color, hairstyles, facial expression, poses, and adding facial hair.
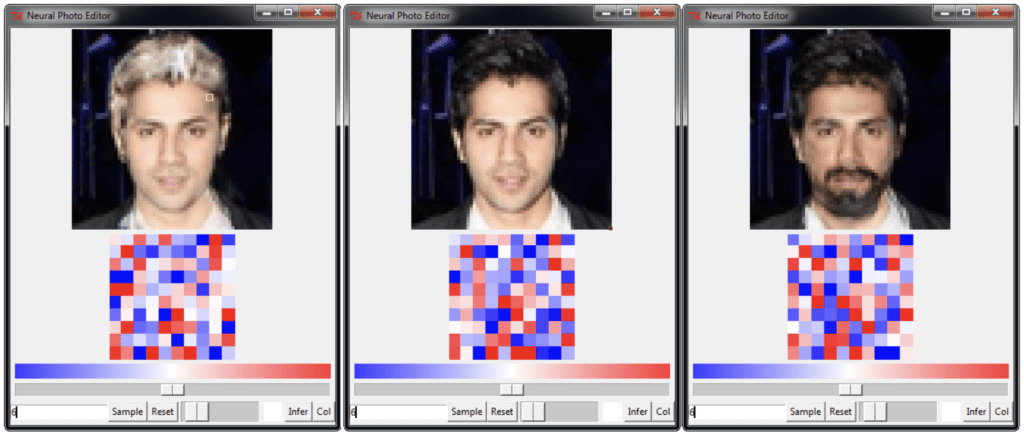
Example of Face Editing Using the Neural Photo Editor Based on VAEs and GANs.Taken from Neural Photo Editing with Introspective Adversarial Networks, 2016.
He Zhang, et al. in their 2017 paper titled “Image De-raining Using a Conditional Generative Adversarial Network” use GANs for image editing, including examples such as removing rain and snow from photographs.

Example of Using a GAN to Remove Rain From PhotographsTaken from Image De-raining Using a Conditional Generative Adversarial Network
Face Aging
Grigory Antipov, et al. in their 2017 paper titled “Face Aging With Conditional Generative Adversarial Networks” use GANs to generate photographs of faces with different apparent ages, from younger to older.

Example of Photographs of Faces Generated With a GAN With Different Apparent Ages.Taken from Face Aging With Conditional Generative Adversarial Networks, 2017.
Zhifei Zhang, in their 2017 paper titled “Age Progression/Regression by Conditional Adversarial Autoencoder” use a GAN based method for de-aging photographs of faces.

Example of Using a GAN to Age Photographs of FacesTaken from Age Progression/Regression by Conditional Adversarial Autoencoder, 2017.
Photo Blending
Huikai Wu, et al. in their 2017 paper titled “GP-GAN: Towards Realistic High-Resolution Image Blending” demonstrate the use of GANs in blending photographs, specifically elements from different photographs such as fields, mountains, and other large structures.

Example of GAN-based Photograph Blending.Taken from GP-GAN: Towards Realistic High-Resolution Image Blending, 2017.
Super Resolution
Christian Ledig, et al. in their 2016 paper titled “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network” demonstrate the use of GANs, specifically their SRGAN model, to generate output images with higher, sometimes much higher, pixel resolution.

Example of GAN-Generated Images With Super Resolution. Taken from Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network, 2016.
Huang Bin, et al. in their 2017 paper tilted “High-Quality Face Image SR Using Conditional Generative Adversarial Networks” use GANs for creating versions of photographs of human faces.

Example of High-Resolution Generated Human FacesTaken from High-Quality Face Image SR Using Conditional Generative Adversarial Networks, 2017.
Subeesh Vasu, et al. in their 2018 paper tilted “Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network” provide an example of GANs for creating high-resolution photographs, focusing on street scenes.

Example of High-Resolution GAN-Generated Photographs of Buildings.Taken from Analyzing Perception-Distortion Tradeoff using Enhanced Perceptual Super-resolution Network, 2018.
Photo Inpainting
Deepak Pathak, et al. in their 2016 paper titled “Context Encoders: Feature Learning by Inpainting” describe the use of GANs, specifically Context Encoders, to perform photograph inpainting or hole filling, that is filling in an area of a photograph that was removed for some reason.

Example of GAN-Generated Photograph Inpainting Using Context Encoders.Taken from Context Encoders: Feature Learning by Inpainting describe the use of GANs, specifically Context Encoders, 2016.
Raymond A. Yeh, et al. in their 2016 paper titled “Semantic Image Inpainting with Deep Generative Models” use GANs to fill in and repair intentionally damaged photographs of human faces.

Example of GAN-based Inpainting of Photographs of Human FacesTaken from Semantic Image Inpainting with Deep Generative Models, 2016.
Yijun Li, et al. in their 2017 paper titled “Generative Face Completion” also use GANs for inpainting and reconstructing damaged photographs of human faces.

Example of GAN Reconstructed Photographs of FacesTaken from Generative Face Completion, 2017.
Clothing Translation
Donggeun Yoo, et al. in their 2016 paper titled “Pixel-Level Domain Transfer” demonstrate the use of GANs to generate photographs of clothing as may be seen in a catalog or online store, based on photographs of models wearing the clothing.

Example of Input Photographs and GAN-Generated Clothing PhotographsTaken from Pixel-Level Domain Transfer, 2016.
Video Prediction
Carl Vondrick, et al. in their 2016 paper titled “Generating Videos with Scene Dynamics” describe the use of GANs for video prediction, specifically predicting up to a second of video frames with success, mainly for static elements of the scene.

Example of Video Frames Generated With a GAN.Taken from Generating Videos with Scene Dynamics, 2016.
3D Object Generation
Jiajun Wu, et al. in their 2016 paper titled “Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling” demonstrate a GAN for generating new three-dimensional objects (e.g. 3D models) such as chairs, cars, sofas, and tables.

Example of GAN-Generated Three Dimensional Objects.Taken from Learning a Probabilistic Latent Space of Object Shapes via 3D Generative-Adversarial Modeling
Matheus Gadelha, et al. in their 2016 paper titled “3D Shape Induction from 2D Views of Multiple Objects” use GANs to generate three-dimensional models given two-dimensional pictures of objects from multiple perspectives.

Example of Three-Dimensional Reconstructions of a Chair From Two-Dimensional Images.Taken from 3D Shape Induction from 2D Views of Multiple Objects, 2016.
Further Reading
This section provides more lists of GAN applications to complement this list.
- gans-awesome-applications: Curated list of awesome GAN applications and demo.
- Some cool applications of GANs, 2018.
- GANs beyond generation: 7 alternative use cases, 2018.
Summary
In this post, you discovered a large number of applications of Generative Adversarial Networks, or GANs.
Did I miss an interesting application of GANs or a great paper on specific GAN application?
Please let me know in the comments.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post 18 Impressive Applications of Generative Adversarial Networks (GANs) appeared first on Machine Learning Mastery.
OhNoCrypto
via https://www.aiupnow.com
Jason Brownlee, Khareem Sudlow



