Generative Adversarial Networks, or GANs for short, are effective at generating large high-quality images.
Most improvement has been made to discriminator models in an effort to train more effective generator models, although less effort has been put into improving the generator models.
The Style Generative Adversarial Network, or StyleGAN for short, is an extension to the GAN architecture that proposes large changes to the generator model, including the use of a mapping network to map points in latent space to an intermediate latent space, the use of the intermediate latent space to control style at each point in the generator model, and the introduction to noise as a source of variation at each point in the generator model.
The resulting model is capable not only of generating impressively photorealistic high-quality photos of faces, but also offers control over the style of the generated image at different levels of detail through varying the style vectors and noise.
In this post, you will discover the Style Generative Adversarial Network that gives control over the style of generated synthetic images.
After reading this post, you will know:
- The lack of control over the style of synthetic images generated by traditional GAN models.
- The architecture of StyleGAN model that introduces control over the style of generated images at different levels of detail.
- Impressive results achieved with the StyleGAN architecture when used to generate synthetic human faces.
Discover how to develop DCGANs, conditional GANs, Pix2Pix, CycleGANs, and more with Keras in my new GANs book, with 29 step-by-step tutorials and full source code.
Let’s get started.

A Gentle Introduction to Style Generative Adversarial Network (StyleGAN)
Photo by Ian D. Keating, some rights reserved.
Overview
This tutorial is divided into four parts; they are:
- Lacking Control Over Synthesized Images
- Control Style Using New Generator Model
- What Is the StyleGAN Model Architecture
- Examples of StyleGAN Generated Images
Lacking Control Over Synthesized Images
Generative adversarial networks are effective at generating high-quality and large-resolution synthetic images.
The generator model takes as input a point from latent space and generates an image. This model is trained by a second model, called the discriminator, that learns to differentiate real images from the training dataset from fake images generated by the generator model. As such, the two models compete in an adversarial game and find a balance or equilibrium during the training process.
Many improvements to the GAN architecture have been achieved through enhancements to the discriminator model. These changes are motivated by the idea that a better discriminator model will, in turn, lead to the generation of more realistic synthetic images.
As such, the generator has been somewhat neglected and remains a black box. For example, the source of randomness used in the generation of synthetic images is not well understood, including both the amount of randomness in the sampled points and the structure of the latent space.
Yet the generators continue to operate as black boxes, and despite recent efforts, the understanding of various aspects of the image synthesis process, […] is still lacking. The properties of the latent space are also poorly understood …
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
This limited understanding of the generator is perhaps most exemplified by the general lack of control over the generated images. There are few tools to control the properties of generated images, e.g. the style. This includes high-level features such as background and foreground, and fine-grained details such as the features of synthesized objects or subjects.
This requires both disentangling features or properties in images and adding controls for these properties to the generator model.
Want to Develop GANs from Scratch?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Control Style Using New Generator Model
The Style Generative Adversarial Network, or StyleGAN for short, is an extension to the GAN architecture to give control over the disentangled style properties of generated images.
Our generator starts from a learned constant input and adjusts the “style” of the image at each convolution layer based on the latent code, therefore directly controlling the strength of image features at different scales
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
The StyleGAN is an extension of the progressive growing GAN that is an approach for training generator models capable of synthesizing very large high-quality images via the incremental expansion of both discriminator and generator models from small to large images during the training process.
In addition to the incremental growing of the models during training, the style GAN changes the architecture of the generator significantly.
The StyleGAN generator no longer takes a point from the latent space as input; instead, there are two new sources of randomness used to generate a synthetic image: a standalone mapping network and noise layers.
The output from the mapping network is a vector that defines the styles that is integrated at each point in the generator model via a new layer called adaptive instance normalization. The use of this style vector gives control over the style of the generated image.
Stochastic variation is introduced through noise added at each point in the generator model. The noise is added to entire feature maps that allow the model to interpret the style in a fine-grained, per-pixel manner.
This per-block incorporation of style vector and noise allows each block to localize both the interpretation of style and the stochastic variation to a given level of detail.
The new architecture leads to an automatically learned, unsupervised separation of high-level attributes (e.g., pose and identity when trained on human faces) and stochastic variation in the generated images (e.g., freckles, hair), and it enables intuitive, scale-specific control of the synthesis
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
What Is the StyleGAN Model Architecture
The StyleGAN is described as a progressive growing GAN architecture with five modifications, each of which was added and evaluated incrementally in an ablative study.
The incremental list of changes to the generator are:
- Baseline Progressive GAN.
- Addition of tuning and bilinear upsampling.
- Addition of mapping network and AdaIN (styles).
- Removal of latent vector input to generator.
- Addition of noise to each block.
- Addition Mixing regularization.
The image below summarizes the StyleGAN generator architecture.
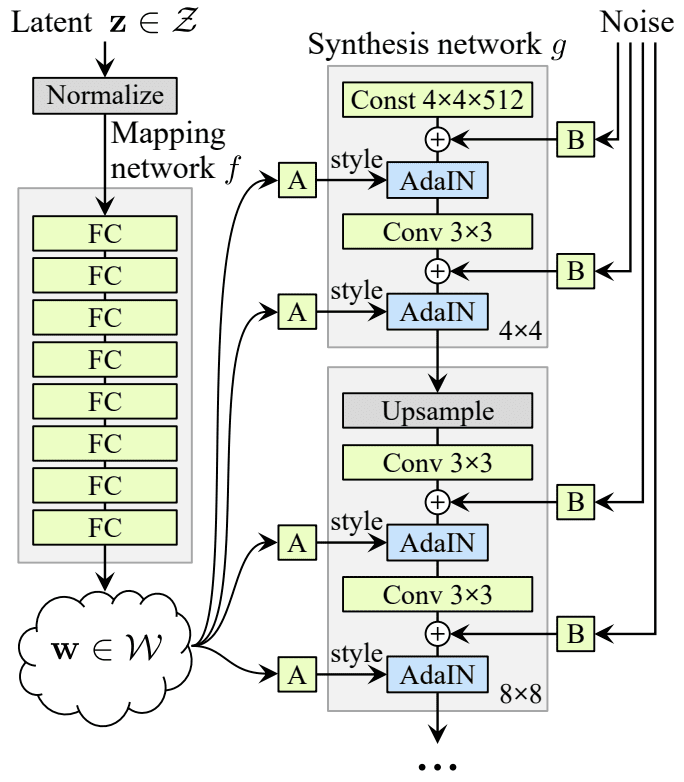
Summary of the StyleGAN Generator Model Architecture.
Taken from: A Style-Based Generator Architecture for Generative Adversarial Networks.
We can review each of these changes in more detail.
1. Baseline Progressive GAN
The StyleGAN generator and discriminator models are trained using the progressive growing GAN training method.
This means that both models start with small images, in this case, 4×4 images. The models are fit until stable, then both discriminator and generator are expanded to double the width and height (quadruple the area), e.g. 8×8.
A new block is added to each model to support the larger image size, which is faded in slowly over training. Once faded-in, the models are again trained until reasonably stable and the process is repeated with ever-larger image sizes until the desired target image size is met, such as 1024×1024.
For more on the progressive growing GAN, see the paper:
2. Bilinear Sampling
The progressive growing GAN uses nearest neighbor layers for upsampling instead of transpose convolutional layers that are common in other generator models.
The first point of deviation in the StyleGAN is that bilinear upsampling layers are unused instead of nearest neighbor.
We replace the nearest-neighbor up/downsampling in both networks with bilinear sampling, which we implement by lowpass filtering the activations with a separable 2nd order binomial filter after each upsampling layer and before each downsampling layer.
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
3. Mapping Network and AdaIN
Next, a standalone mapping network is used that takes a randomly sampled point from the latent space as input and generates a style vector.
The mapping network is comprised of eight fully connected layers, e.g. it is a standard deep convolutional neural network.
For simplicity, we set the dimensionality of both [the latent and intermediate latent] spaces to 512, and the mapping f is implemented using an 8-layer MLP …
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
The style vector is then transformed and incorporated into each block of the generator model after the convolutional layers via an operation called adaptive instance normalization or AdaIN.
The AdaIN layers involve first standardizing the output of feature map to a standard Gaussian, then adding the style vector as a bias term.
Learned affine transformations then specialize [the intermediate latent vector] to styles y = (ys, yb) that control adaptive instance normalization (AdaIN) operations after each convolution layer of the synthesis network g.
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
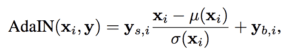
Calculation of the adaptive instance normalization (AdaIN) in the StyleGAN.
Taken from: A Style-Based Generator Architecture for Generative Adversarial Networks.
The addition of the new mapping network to the architecture also results in the renaming of the generator model to a “synthesis network.”
4. Removal of Latent Point Input
The next change involves modifying the generator model so that it no longer takes a point from the latent space as input.
Instead, the model has a constant 4x4x512 constant value input in order to start the image synthesis process.
5. Addition of Noise
The output of each convolutional layer in the synthesis network is a block of activation maps.
Gaussian noise is added to each of these activation maps prior to the AdaIN operations. A different sample of noise is generated for each block and is interpreted using per-layer scaling factors.
These are single-channel images consisting of uncorrelated Gaussian noise, and we feed a dedicated noise image to each layer of the synthesis network. The noise image is broadcasted to all feature maps using learned per-feature scaling factors and then added to the output of the corresponding convolution …
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
This noise is used to introduce style-level variation at a given level of detail.
6. Mixing regularization
Mixing regularization involves first generating two style vectors from the mapping network.
A split point in the synthesis network is chosen and all AdaIN operations prior to the split point use the first style vector and all AdaIN operations after the split point get the second style vector.
… we employ mixing regularization, where a given percentage of images are generated using two random latent codes instead of one during training.
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
This encourages the layers and blocks to localize the style to specific parts of the model and corresponding level of detail in the generated image.
Examples of StyleGAN Generated Images
The StyleGAN is both effective at generating large high-quality images and at controlling the style of the generated images.
In this section, we will review some examples of generated images.
A video demonstrating the capability of the model was released by the authors of the paper, providing a useful overview.
High-Quality Faces
The image below taken from the paper shows synthetic faces generated with the StyleGAN with the sizes 4×4, 8×8, 16×16, and 32×32.

Example of High-Quality Generated Faces Using the StyleGAN.
Taken from: A Style-Based Generator Architecture for Generative Adversarial Networks.
Varying Style by Level of Detail
The use of different style vectors at different points of the synthesis network gives control over the styles of the resulting image at different levels of detail.
For example, blocks of layers in the synthesis network at lower resolutions (e.g. 4×4 and 8×8) control high-level styles such as pose and hairstyle. Blocks of layers in the model of the network (e.g. as 16×16 and 32×32) control hairstyles and facial expression. Finally, blocks of layers closer to the output end of the network (e.g. 64×64 to 1024×1024) control color schemes and very fine details.
The image below taken from the paper shows generated images on the left and across the top. The two rows of intermediate images are examples of the style vectors used to generate the images on the left, where the style vectors used for the images on the top are used only in the lower levels. This allows the images on the left to adopt high-level styles such as pose and hairstyle from the images on the top in each column.
Copying the styles corresponding to coarse spatial resolutions (4^2 – 8^2) brings high-level aspects such as pose, general hair style, face shape, and eyeglasses from source B, while all colors (eyes, hair, lighting) and finer facial features resemble A.
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.

Example of One Set of Generated Faces (Left) Adopting the Coarse Style of Another Set of Generated Faces (Top)
Taken from: A Style-Based Generator Architecture for Generative Adversarial Networks.
Varying Style by Level of Detail
The authors varied the use of noise at different levels of detail in the model (e.g. fine, middle, coarse), much like the previous example of varying style.
The result is that noise gives control over the generation of detail, from broader structure when noise is used in the coarse blocks of layers to the generation of fine detail when noise is added to the layers closer to the output of the network.
We can see that the artificial omission of noise leads to featureless “painterly” look. Coarse noise causes large-scale curling of hair and appearance of larger background features, while the fine noise brings out the finer curls of hair, finer background detail, and skin pores.
— A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.

Example of Varying Noise at Different Levels of the Generator Model.
Taken from: A Style-Based Generator Architecture for Generative Adversarial Networks.
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
- A Style-Based Generator Architecture for Generative Adversarial Networks, 2018.
- Progressive Growing of GANs for Improved Quality, Stability, and Variation, 2017.
- StyleGAN – Official TensorFlow Implementation, GitHub.
- StyleGAN Results Video, YouTube.
Summary
In this post, you discovered the Style Generative Adversarial Network that gives control over the style of generated synthetic images.
Specifically, you learned:
- The lack of control over the style of synthetic images generated by traditional GAN models.
- The architecture of StyleGAN model GAN model that introduces control over the style of generated images at different levels of detail
- Impressive results achieved with the StyleGAN architecture when used to generate synthetic human faces.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post A Gentle Introduction to Style Generative Adversarial Networks (StyleGAN) appeared first on Machine Learning Mastery.
Ai
via https://www.AiUpNow.com
Jason Brownlee, Khareem Sudlow

