
Googlebot obeys only specific commands, ignores forms and cookies, and crawls only properly coded links. Thus errors and oversights in the construction of a site can impact the ability to crawl and index it.
It’s natural to assume that everything humans see on a website is accessible to search engines. But that’s not the case.
Googlebot can reportedly fill out forms, accept cookies, and crawl all forms of links. But accessing these elements would consume seemingly unlimited crawling and indexing resources.
Thus Googlebot obeys only certain commands, ignores forms and cookies, and crawls only the links coded with a proper anchor tag and href.
What follows are seven items that block Googlebot and other search engine bots from crawling (and indexing) all of your web pages.
1. Location-based Pages
Sites with locale-adaptive pages detect a visitor’s IP address and then display content based on that location. But it’s not foolproof. A visitor’s IP could appear to be in Boston even though she lives in New York. She would therefore receive content about Boston, which she doesn’t want.
Googlebot’s default IP is from the San Jose, Calif. area. Hence Googlebot would see only content related to that region.
Location-based content upon first entry into the site is fine. But subsequent content should be based on links clicked, rather than an IP address.
This invisible barrier to organic search success is one of the hardest to sniff out.
2. Cookie-based Content
Sites place cookies on a web browser to personalize a visitor’s experience, such as language preferences or click paths for rendering breadcrumbs. Content that visitors access solely due to cookies, rather than clicking a link, will not be accessible to search engine bots.
For example, some sites serve country and language content based on cookies. If you visit an online store and choose to read in French, a cookie is set and the rest of your visit on the site proceeds in French. The URLs stay the same as when the site was in English, but the content is different.
The site owner presumably wants French-language content to rank in organic search to bring French-speaking people to the site. But it won’t. When the URL doesn’t change as content changes, search engines are unable to crawl or rank the alternative versions.
3. Uncrawlable JavaScript Links
For Google, a link is not a link unless it contains both an anchor tag and an href to a specific URL. Anchor text is also desirable as it establishes the relevance of the page being linked to.
The hypothetical markup below highlights the difference to Googlebot between crawlable links and uncrawlable — “Will be crawled” vs. “Not crawled.”
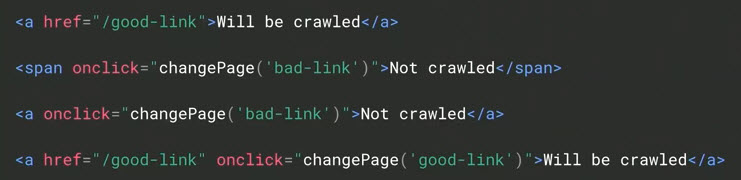
Google requires links to contain both an anchor tag and an href to a specific URL. In this example, Googlebot will crawl the first and fourth lines. But it won’t crawl the second and third.
Ecommerce sites tend to code their links using onclicks (a mouseover dropdown linking to other pages) instead of anchor tags. While that works for humans, Googlebot does not recognize them as crawlable links. Thus the pages linked in this manner can have indexation problems.
4. Hashtag URLs
AJAX is a form of JavaScript that refreshes content without reloading the page. The refreshed content inserts a hashtag (a pound sign: #) in the page’s URL. Unfortunately, hashtags don’t always reproduce the intended content on subsequent visits. If search engines indexed hashtag URLs, the content might not be what searchers were looking for.
While most search engine optimizers understand the indexation issues inherent with hashtag URLs, marketers are often surprised to learn this basic element of their URL structure is causing organic search woes.
5. Robots.txt Disallow
The robots.txt file is an archaic text document at the root of a site. It tells bots (that choose to obey) which content to crawl via, typically, the disallow command.
Disallow commands do not prevent indexation. But they can prevent pages from ranking due to the bots’ inability to determine the page’s relevance.
Disallow commands can appear in robots.txt files accidentally — such as when a redesign is pushed live — thus blocking search bots from crawling the entire site. The existence of a disallow in the robots.txt file is one of the first things to check for a sudden drop in organic search traffic.
6. Meta Robots Noindex
The noindex attribute of a URL’s meta tag commands search engine bots not to index that page. It’s applied on a page-by-page basis, rather than in a single file that governs the entire site, such as disallow commands.
However, noindex attributes are more powerful than disallows because they halt indexation.
Like disallow commands, noindex attributes can be accidentally pushed live. They’re one of the most difficult blockers to uncover.
7. Incorrect Canonical Tags
Canonical tags identify which page to index out of multiple identical versions. Canonical tags are important weapons to prevent duplicate content. All noncanonical pages attribute their link authority — the value that pages linking to them convey — to the canonical URL. Noncanonical pages are not indexed.
Canonical tags are tucked away in source code. Errors can be difficult to detect. If desired pages on your site aren’t indexed, bad canonical tags may be the culprits.
Ecommerce
via https://www.aiupnow.com
Jill Kocher Brown, Khareem Sudlow

