 Is bias in AI self-reinforcing? Decision-making systems that impact criminal justice, financial institutions, human resources, and many other areas often have bias. This is especially true of algorithmic systems that learn from historical data, which tends to reflect existing societal biases. In many high-stakes applications, like hiring and lending, these decision-making systems may even reshape the underlying populations. When the system is retrained on future data, it may become not less but more detrimental to historically disadvantaged groups. In order to build AI systems that are aligned with desirable long-term societal outcomes, we need to understand when and why such negative feedback loops occur, and we need to learn how to prevent them.
Is bias in AI self-reinforcing? Decision-making systems that impact criminal justice, financial institutions, human resources, and many other areas often have bias. This is especially true of algorithmic systems that learn from historical data, which tends to reflect existing societal biases. In many high-stakes applications, like hiring and lending, these decision-making systems may even reshape the underlying populations. When the system is retrained on future data, it may become not less but more detrimental to historically disadvantaged groups. In order to build AI systems that are aligned with desirable long-term societal outcomes, we need to understand when and why such negative feedback loops occur, and we need to learn how to prevent them.
We explored these negative feedback loops and related questions in our paper, “The Disparate Equilibria of Algorithmic Decision Making when Individuals Invest Rationally,” to be presented at the third annual ACM Conference on Fairness, Accountability, and Transparency (ACM FAT* 2020) in Barcelona, Spain. This research started during my internship at Microsoft Research, and was joint work with wonderful collaborators: Ashia Wilson, Nika Haghtalab of Cornell University (who was a postdoctoral researcher at Microsoft Research at the time), Adam Tauman Kalai, Christian Borgs, and Jennifer Chayes.
Examining an economic model of individual response to institutions’ assessment rules and finding stable equilibria
In this work, we consider an economic model of how individuals respond to a classification algorithm, focusing on settings where each individual desires a positive classification (in other words, a positive reward). This includes many important applications, such as hiring and school admissions, where the reward gained in these scenarios is an individual being hired or admitted.
We assume that people invest in a positive qualification, such as gaining job skills or achieving higher academic success, based on the expected gain for their demographic group under the company’s or school’s current hiring or admittance practices, which in our work translates into an assessment rule. In these situations, a person must decide whether it is worth investing in these qualifications, resulting in a binary outcome of answering “yes” or “no.” The decision to invest has a cost, such as tuition or time.
The assessment rule assesses the qualification of individuals based on their observable characteristics, such as resumes or SAT scores. It is frequently updated on the current distribution of individuals to maximize institutional benefit. We are interested in the long-term behavior of such dynamics: What is the assessment rule used by the institution at equilibrium? In this case, an equilibrium assessment rule is an assessment rule that remains the same even after individuals respond to it. By understanding the stable equilibria that the dynamics tend toward, we can characterize how individuals will invest in the long term.
The idea that individuals make a rational decision to invest in a positive qualification given the institution’s assessment rule is not new. Economists Coate and Loury first introduced this model in 1993 in order to understand the long-run effectiveness of affirmative action.
Unlike this earlier work in the area, we study high-dimensional feature spaces and general model classes for the assessment rule, which are typical in applications of machine learning to high-stakes decision making. We also allow observable features to be distributed differently across demographic groups. In the real world, this is often the case.
A real-world example: A university’s assessment rule impacts a group of individuals’ incentive to apply
Consider the following example of a negative feedback loop captured by this model. A university makes admissions decisions based on an individual’s SAT score, which is an imperfect indicator of academic qualification. Academic qualification is assumed to be a binary variable, that is, an individual can be either qualified or unqualified. In the first group of students (indicated as blue in the figure below), individuals who are academically qualified score above 1200; in the second group (indicated as orange in the figure below), such individuals score above 1500.
The school’s initial assessment rule for admission is a threshold at 1400, which lowers the incentive for students from the first group, who have scores lower than that threshold, to invest in their academic qualifications relative to students from the second group. Therefore, there are fewer academically qualified individuals scoring in the 1200 to 1500 range in the next year, prompting the school to change the assessment rule to a higher threshold at 1500. This further lowers the incentive for students from the first group to pursue academic success.
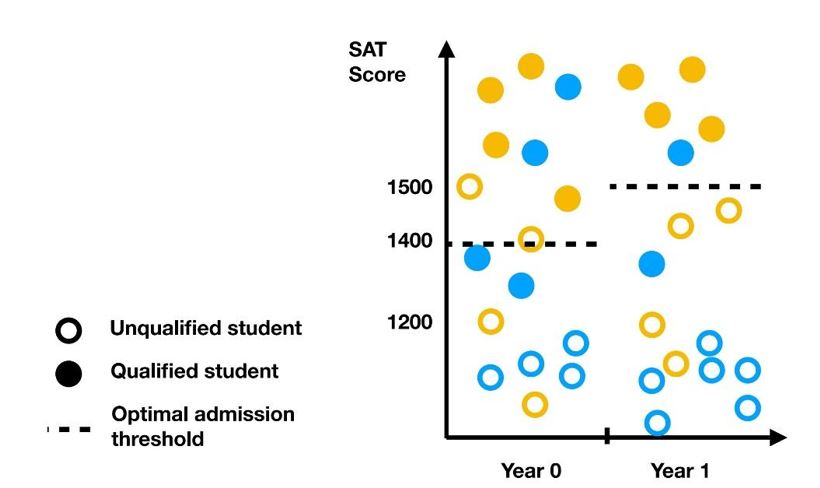
The figure above hypothetically shows how the distribution of qualified and unqualified students in two groups might change in response to the threshold for admission, under the model of individual response. In this scenario, fewer qualified students from the blue group apply as the SAT score threshold for admission increases from 1400 to 1500.
More generally, our work finds that heterogeneity across groups (in other words, the lack of one decision-making model that performs optimally for every group) tends to lead to the multiple equilibrium assessment rules that each favor a different group. In this case, all stable long-term outcomes will disadvantage some group—that is, their qualification rate will be lower than that of another group (or other groups), as depicted in the example above.
Another cause of negative feedback loops is the lack of realizability, which is the existence of an errorless way to assess qualifications of individuals from observable features. Sometimes the outcome is inherently stochastic, making it impossible to implement assessment rules with zero error. As a result, the institution’s assessment rule is sensitive to the underlying qualification rate of each group, which is determined by individuals’ investment decisions.
Potential interventions to correct for negative impacts to certain groups
In the paper, we also consider two interventions: decoupling the assessment rule by group (using a different assessment rule for each group instead of a joint assessment rule) and subsidizing the cost of investment for a disadvantaged group. We find that under these dynamics, the welfare effects of decoupling crucially depend on realizability as well as the initial qualification rates. If the classification problem is non-realizable, it is in fact possible for decoupling to hurt a group with low initial qualification rate by reinforcing the status quo, whereas a joint assessment rule would have increased that group’s qualification rates in the long run.
We find that subsidizing individuals’ investment cost (such as subsidizing tuition for a top high school) increases the qualification rate of the disadvantaged group at equilibrium, regardless of realizability. In our setting, subsidies affect the qualification of individuals directly and are different from those studied under strategic manipulation (Hu et al., 2019).
These previous studies involve subsidizing individuals’ costs to manipulate their features without changing the underlying qualification (such as subsidizing SAT exam preparation without changing the student’s qualification for college) and could have adverse effects on disadvantaged groups. In contrast, our work suggests the effectiveness of subsidizing opportunities for a disadvantaged group to directly improve their outcomes.
To further explore the effects of these interventions, refer to our paper for relevant experiments on semi-simulated data.
Lessons learned about feedback loops and where research goes from here
In this work we studied a natural model of feedback loops in algorithmic decision making. We found that common properties of real data, namely heterogeneity across groups and the lack of realizability, lead to undesirable long-term outcomes that disadvantage one or more groups. We also examined two interventions and showed their impact depends crucially on the underlying dynamics.
These lessons underscore the need to better understand the dynamics of algorithmic decision making. The assessment rule used by any AI system often has a much larger impact beyond its intended scope and its immediate purpose as conceived by the institution. In order to build AI systems that are aligned with the long-term welfare of all people, we need a principled view of how different feedback loops arise and how to incorporate that knowledge into the design of real decision-making systems. Our work is just one step in this direction, and there remain many important questions for future work.
The post When bias begets bias: A source of negative feedback loops in AI systems appeared first on Microsoft Research.
Is bias in AI self-reinforcing? Decision-making systems that impact criminal justice, financial institutions, human resources, and many other areas often have bias. This is especially true of algorithmic systems that learn from historical data, which tends to reflect existing societal biases. In many high-stakes applications, like hiring and lending, these decision-making systems may even reshape […]
The post When bias begets bias: A source of negative feedback loops in AI systems appeared first on Microsoft Research.
by: Alexis Hagen via https://www.AiUpNow.com/
