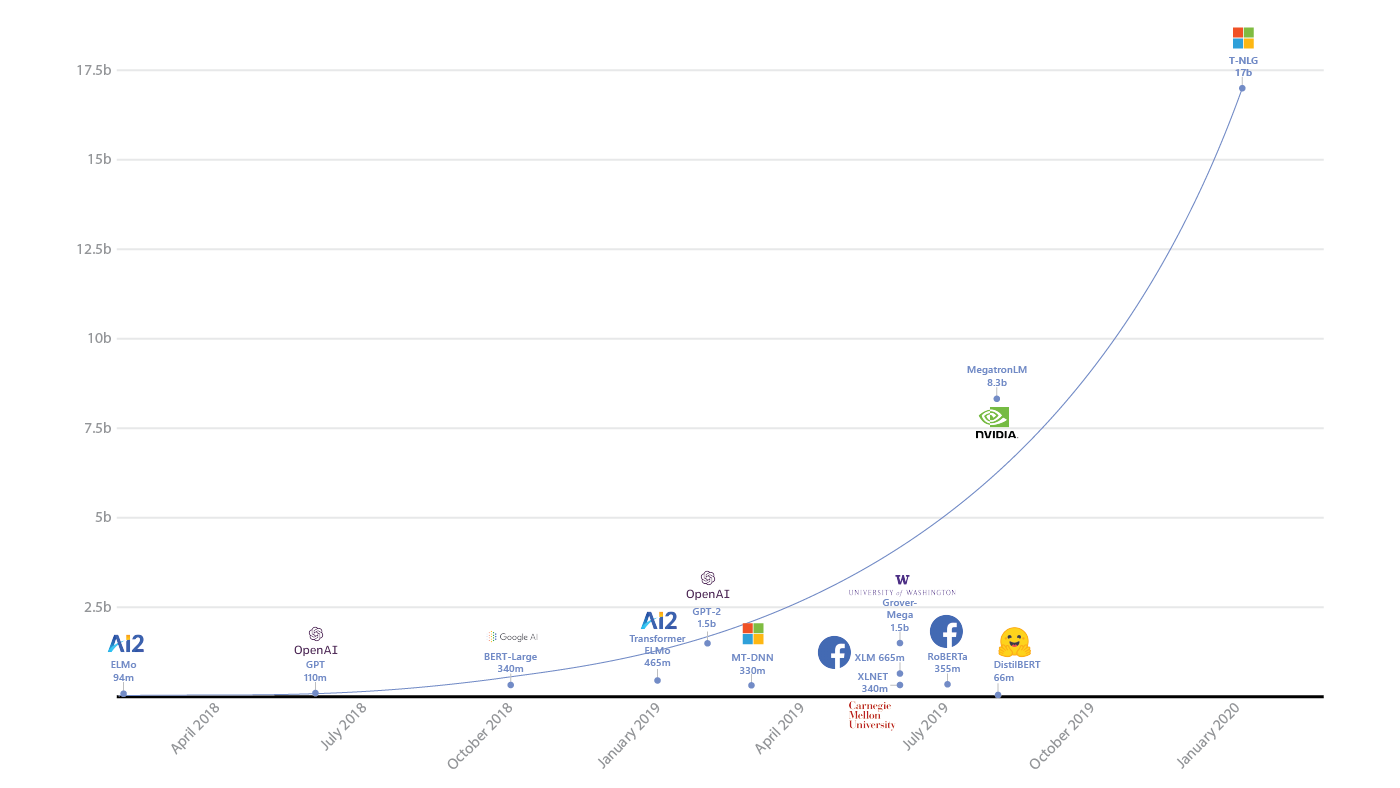
This figure was adapted from a similar image published in DistilBERT.
Turing Natural Language Generation (T-NLG) is a 17 billion parameter language model by Microsoft that outperforms the state of the art on many downstream NLP tasks. We present a demo of the model, including its freeform generation, question answering, and summarization capabilities, to academics for feedback and research purposes. <|endoftext|>
– This summary was generated by the Turing-NLG language model itself.
Massive deep learning language models (LM), such as BERT and GPT-2, with billions of parameters learned from essentially all the text published on the internet, have improved the state of the art on nearly every downstream natural language processing (NLP) task, including question answering, conversational agents, and document understanding among others.
Better natural language generation can be transformational for a variety of applications, such as assisting authors with composing their content, saving one time by summarizing a long piece of text, or improving customer experience with digital assistants. Following the trend that larger natural language models lead to better results, Microsoft Project Turing is introducing Turing Natural Language Generation (T-NLG), the largest model ever published at 17 billion parameters, which outperforms the state of the art on a variety of language modeling benchmarks and also excels when applied to numerous practical tasks, including summarization and question answering. This work would not be possible without breakthroughs produced by the DeepSpeed library (compatible with PyTorch) and ZeRO optimizer, which can be explored more in this accompanying blog post.
We are releasing a private demo of T-NLG, including its freeform generation, question answering, and summarization capabilities, to a small set of users within the academic community for initial testing and feedback.
T-NLG: Benefits of a large generative language model
T-NLG is a Transformer-based generative language model, which means it can generate words to complete open-ended textual tasks. In addition to completing an unfinished sentence, it can generate direct answers to questions and summaries of input documents.
Generative models like T-NLG are important for NLP tasks since our goal is to respond as directly, accurately, and fluently as humans can in any situation. Previously, systems for question answering and summarization relied on extracting existing content from documents that could serve as a stand-in answer or summary, but they often appear unnatural or incoherent. With T-NLG we can naturally summarize or answer questions about a personal document or email thread.
We have observed that the bigger the model and the more diverse and comprehensive the pretraining data, the better it performs at generalizing to multiple downstream tasks even with fewer training examples. Therefore, we believe it is more efficient to train a large centralized multi-task model and share its capabilities across numerous tasks rather than train a new model for every task individually.
Pretraining T-NLG: Hardware and software breakthroughs
Any model with more than 1.3 billion parameters cannot fit into a single GPU (even one with 32GB of memory), so the model itself must be parallelized, or broken into pieces, across multiple GPUs. We took advantage of several hardware and software breakthroughs to achieve training T-NLG:
1. We leverage a NVIDIA DGX-2 hardware setup, with InfiniBand connections so that communication between GPUs is faster than previously achieved.
2. We apply tensor slicing to shard the model across four NVIDIA V100 GPUs on the NVIDIA Megatron-LM framework.
3. DeepSpeed with ZeRO allowed us to reduce the model-parallelism degree (from 16 to 4), increase batch size per node by fourfold, and reduce training time by three times. DeepSpeed makes training very large models more efficient with fewer GPUs, and it trains at batch size of 512 with only 256 NVIDIA GPUs compared to 1024 NVIDIA GPUs needed by using Megatron-LM alone. DeepSpeed is compatible with PyTorch.
The resulting T-NLG model has 78 Transformer layers with a hidden size of 4256 and 28 attention heads. To make results comparable to Megatron-LM, we pretrained the model with the same hyperparameters and learning schedule as Megatron-LM using autoregressive generation loss for 300,000 steps of batch size 512 on sequences of 1024 tokens. The learning schedule followed 3,200 steps of linear warmup up to a maximum learning rate of 1.5×10-4 and cosine decay over 500,000 steps, with FP16. We trained the model on the same type of data that Megatron-LM models were trained on.
We also compared the performance of the pretrained T-NLG model on standard language tasks such as WikiText-103 perplexity (lower is better) and LAMBADA next word prediction accuracy (higher is better). The table below shows that we achieve the new state of the art on both LAMBADA and WikiText-103. Megatron-LM is the publicly released results from the NVIDIA Megatron model.

*Open AI used additional processing (stopword filtering) to achieve higher numbers than the model achieved alone. Neither Megatron nor T-NLG use this stopword filtering technique.
Figure 1 below shows how T-NLG performs when compared with Megatron-LM on validation perplexity.

Figure 1: Comparison of the validation perplexity of Megatron-8B parameter model (orange line) vs T-NLG 17B model during training (blue and green lines). The dashed line represents the lowest validation loss achieved by the current public state of the art model. The transition from blue to green in the figure indicates where T-NLG outperforms public state of the art.
Direct question answering and zero shot question capabilities
Many web search users are accustomed to seeing a direct answer card displayed at the top of the results page when they ask a question. Most of those cards show an answer sentence within the context of the paragraph it originated from. Our goal is to more plainly satisfy users’ information needs by responding directly to their question. For instance, most search engines would highlight the name “Tristan Prettyman” below when showing the full passage (see example below).
| Question | Who was Jason Mraz engaged to? |
| Passage | Mraz was engaged to singer/songwriter and long-time close friend Tristan Prettyman on Christmas Eve 2010; they broke off the engagement six months later. |
| “Direct” Answer | Jason Mraz was engaged to Tristan Prettyman. |
Instead, T-NLG will directly answer the question with a complete sentence. This capability is more important outside of web search—for example, this can power AI assistants to intelligently respond when a user asks a question about their personal data such as emails or Word documents.
The model is also capable of “zero shot” question answering, meaning answering without a context passage. For the examples below, there was no passage given to the model, just the question. In these cases, the model relies on knowledge gained during pretraining to generate an answer.

Since ROUGE scores with the ground truth answer don’t capture other aspects of quality, like factual correctness and grammatical correctness, we asked human annotators to evaluate those qualities for our previous baseline system—an LSTM model similar to CopyNet—and our current T-NLG model. There is still work to be done to enable automatic evaluation of factual correctness.

We also note that a larger pretrained model requires fewer instances of downstream tasks to learn them well. We only had, at most, 100,000 examples of “direct” answer question-passage-answer triples, and even after only a few thousand instances of training, we had a model that outperformed the LSTM baseline that was trained on multiple epochs of the same data. This observation has real business impact, since it is expensive to collect annotated supervised data.
Abstractive summarization with less supervision
There are two types of summarization in the NLP literature: extractive—taking a small number of sentences from the document as a surrogate of a summary—and abstractive—generating a summary with an NLG model as a human would. Rather than copying existing content, our goal for T-NLG is to write human-like abstractive summaries for a wide range of text documents: emails, blog posts, Word documents, and even Excel sheets and PowerPoint presentations. One of the main challenges is a lack of supervised training data for all these scenarios: humans don’t always explicitly summarize each of these document types. The power of T-NLG is that it is already so adept at understanding text that it doesn’t need much supervision to outperform all the techniques we’ve employed previously.
To make T-NLG as versatile as possible for summarizing different types of text, we finetuned the T-NLG model in a multi-task fashion on nearly all publicly available summarization datasets, amounting to approximately four million training instances. We report ROUGE scores (a proxy for how well the generated summary exactly matches the unigrams and bigrams in a reference summary) to compare with another recent Transformer-based language model known as PEGASUS and previous state of the art models.
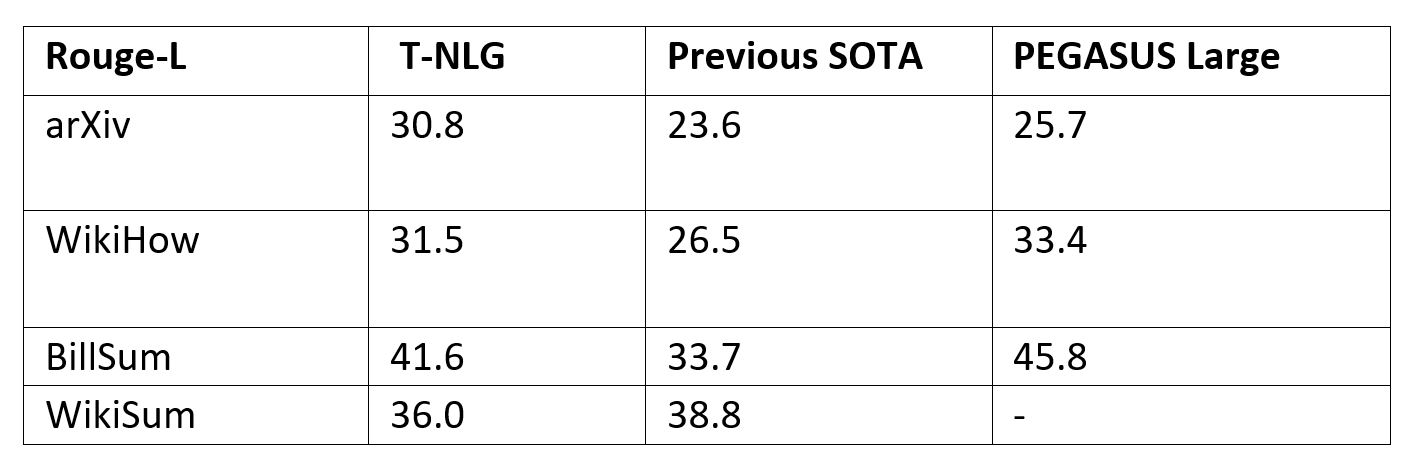
Note that T-NLG is trained in a multi-task fashion, where it is trained on all datasets simultaneously. Since ROUGE evaluation is known to be flawed for summarization tasks, (a good abstractive summary can be written in many ways), we include a few output summaries of publicly available articles for comparison below.
| Link to original text | T-NLG Summary |
| “Microsoft will be carbon negative by 2030” by Brad Smith, Official Microsoft Blog” | Microsoft is committed to being carbon negative by 2030. We are launching an aggressive program to cut our carbon emissions by more than half by 2030, both for our direct emissions and for our entire supply and value chain. We are also launching an initiative to use Microsoft technology to help our suppliers and customers reduce their own carbon footprints and a new $1 billion climate innovation fund to accelerate the development of carbon reduction, capture, and removal technologies that will help us and the world become carbon negative. In addition to our aggressive carbon goals, we are launching a new Climate Innovation Fund to accelerate carbon reduction and removal opportunities. We are also launching a program to use our technology to improve the efficiency of our supply chain and reduce our own carbon footprint as well… |
| “The Next Word: Where will predictive text take us?” by John Seabrook, The New Yorker | “Smart” compose is a feature that suggests what going to type next, based on your past e-mails and your current thoughts. But what happens when you let the A.I. decide what you want to say next? |
T-NLG future applications
T-NLG has advanced the state of the art in natural language generation, providing new opportunities for Microsoft and our customers. Beyond saving our users time by summarizing documents and emails, T-NLG can enhance experiences with the Microsoft Office suite by offering writing assistance to authors and answering questions that readers may ask about a document. Furthermore, it paves the way for more fluent chatbots and digital assistants, as natural language generation can help businesses with customer relationship management and sales by conversing with customers. We are excited by the new possibilities as we continue to advance the quality of language models.
About Project Turing: T-NLG is part of a larger initiative called Project Turing, an applied research group that works to evolve Microsoft products with the adoption of deep learning for both text and image processing. Our work is actively being integrated into multiple Microsoft products including Bing, Office, and Xbox. If you are excited about cutting-edge deep learning research and applications in NLP, or want to learn more, please see our careers page.
If you would like to nominate your organization for a private preview of Semantic Search by Project Turing, submit here.
The post Turing-NLG: A 17-billion-parameter language model by Microsoft appeared first on Microsoft Research.
Turing Natural Language Generation (T-NLG) is a 17 billion parameter language model by Microsoft that outperforms the state of the art on many downstream NLP tasks. We present a demo of the model, including its freeform generation, question answering, and summarization capabilities, to academics for feedback and research purposes. – This summary was generated by […]
The post Turing-NLG: A 17-billion-parameter language model by Microsoft appeared first on Microsoft Research.
by: Alexis Hagen via https://www.AiUpNow.com/
