Imbalanced classification is primarily challenging as a predictive modeling task because of the severely skewed class distribution.
This is the cause for poor performance with traditional machine learning models and evaluation metrics that assume a balanced class distribution.
Nevertheless, there are additional properties of a classification dataset that are not only challenging for predictive modeling but also increase or compound the difficulty when modeling imbalanced datasets.
In this tutorial, you will discover data characteristics that compound the challenge of imbalanced classification.
After completing this tutorial, you will know:
- Imbalanced classification is specifically hard because of the severely skewed class distribution and the unequal misclassification costs.
- The difficulty of imbalanced classification is compounded by properties such as dataset size, label noise, and data distribution.
- How to develop an intuition for the compounding effects on modeling difficulty posed by different dataset properties.
Discover SMOTE, one-class classification, cost-sensitive learning, threshold moving, and much more in my new book, with 30 step-by-step tutorials and full Python source code.
Let’s get started.

Problem Characteristics That Make Imbalanced Classification Hard
Photo by Joshua Damasio, some rights reserved.
Tutorial Overview
This tutorial is divided into four parts; they are:
- Why Imbalanced Classification Is Hard
- Compounding Effect of Dataset Size
- Compounding Effect of Label Noise
- Compounding Effect of Data Distribution
Why Imbalanced Classification Is Hard
Imbalanced classification is defined by a dataset with a skewed class distribution.
This is often exemplified by a binary (two-class) classification task where most of the examples belong to class 0 with only a few examples in class 1. The distribution may range in severity from 1:2, 1:10, 1:100, or even 1:1000.
Because the class distribution is not balanced, most machine learning algorithms will perform poorly and require modification to avoid simply predicting the majority class in all cases. Additionally, metrics like classification lose their meaning and alternate methods for evaluating predictions on imbalanced examples are required, like ROC area under curve.
This is the foundational challenge of imbalanced classification.
- Skewed Class Distribution
An additional level of complexity comes from the problem domain from which the examples were drawn.
It is common for the majority class to represent a normal case in the domain, whereas the minority class represents an abnormal case, such as a fault, fraud, outlier, anomaly, disease state, and so on. As such, the interpretation of misclassification errors may differ across the classes.
For example, misclassifying an example from the majority class as an example from the minority class called a false-positive is often not desired, but less critical than classifying an example from the minority class as belonging to the majority class, a so-called false negative.
This is referred to as cost sensitivity of misclassification errors and is a second foundational challenge of imbalanced classification.
- Unequal Cost of Misclassification Errors
These two aspects, the skewed class distribution and cost sensitivity, are typically referenced when describing the difficulty of imbalanced classification.
Nevertheless, there are other characteristics of the classification problem that, when combined with these properties, compound their effect. These are general characteristics of classification predictive modeling that magnify the difficulty of the imbalanced classification task.
Class imbalance was widely acknowledged as a complicating factor for classification. However, some studies also argue that the imbalance ratio is not the only cause of performance degradation in learning from imbalanced data.
— Page 253, Learning from Imbalanced Data Sets, 2018.
There are many such characteristics, but perhaps three of the most common include:
- Dataset Size.
- Label Noise.
- Data Distribution.
It is important to not only acknowledge these properties but to also specifically develop an intuition for their impact. This will allow you to select and develop techniques to address them in your own predictive modeling projects.
Understanding these data intrinsic characteristics, as well as their relationship with class imbalance, is crucial for applying existing and developing new techniques to deal with imbalance data.
— Pages 253-254, Learning from Imbalanced Data Sets, 2018.
In the following sections, we will take a closer look at each of these properties and their impact on imbalanced classification.
Want to Get Started With Imbalance Classification?
Take my free 7-day email crash course now (with sample code).
Click to sign-up and also get a free PDF Ebook version of the course.
Compounding Effect of Dataset Size
Dataset size simply refers to the number of examples collected from the domain to fit and evaluate a predictive model.
Typically, more data is better as it provides more coverage of the domain, perhaps to a point of diminishing returns.
Specifically, more data provides better representation of combinations and variance of features in the feature space and their mapping to class labels. From this, a model can better learn and generalize a class boundary to discriminate new examples in the future.
If the ratio of examples in the majority class to the minority class is somewhat fixed, then we would expect that we would have more examples in the minority class as the size of the dataset is scaled up.
This is good if we can collect more examples.
It is a problem typically because data is hard or expensive to collect and we often collect and work with a lot less data than we might prefer. As such, this can dramatically impact our ability to gain a large enough or representative sample of examples from the minority class.
A problem that often arises in classification is the small number of training instances. This issue, often reported as data rarity or lack of data, is related to the “lack of density” or “insufficiency of information”.
— Page 261, Learning from Imbalanced Data Sets, 2018.
For example, for a modest classification task with a balanced class distribution, we might be satisfied with thousands or tens of thousands of examples in order to develop, evaluate, and select a model.
A balanced binary classification with 10,000 examples would have 5,000 examples of each class. An imbalanced dataset with a 1:100 distribution with the same number of examples would only have 100 examples of the minority class.
As such, the size of the dataset dramatically impacts the imbalanced classification task, and datasets that are thought large in general are, in fact, probably not large enough when working with an imbalanced classification problem.
Without a sufficient large training set, a classifier may not generalize characteristics of the data. Furthermore, the classifier could also overfit the training data, with a poor performance in out-of-sample tests instances.
— Page 261, Learning from Imbalanced Data Sets, 2018.
To help, let’s make this concrete with a worked example.
We can use the make_classification() scikit-learn function to create a dataset of a given size with a ratio of about 1:100 examples (1 percent to 99 percent) in the minority class to the majority class.
...
# create the dataset
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
We can then create a scatter plot of the dataset and color the points for each class with a septate color to get an idea of the spatial relationship for the examples.
...
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
This process can then be repeated with different datasets sizes to show how the class imbalance is impacted visually. We will compare datasets with 100, 1,000, 10,000, and 100,000 examples.
The complete example is listed below.
# vary the dataset size for a 1:100 imbalanced dataset
from collections import Counter
from sklearn.datasets import make_classification
from matplotlib import pyplot
from numpy import where
# dataset sizes
sizes = [100, 1000, 10000, 100000]
# create and plot a dataset with each size
for i in range(len(sizes)):
# determine the dataset size
n = sizes[i]
# create the dataset
X, y = make_classification(n_samples=n, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=0, random_state=1)
# summarize class distribution
counter = Counter(y)
print('Size=%d, Ratio=%s' % (n, counter))
# define subplot
pyplot.subplot(2, 2, 1+i)
pyplot.title('n=%d' % n)
pyplot.xticks([])
pyplot.yticks([])
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
# show the figure
pyplot.show()
Running the example creates and plots the same dataset with a 1:100 class distribution using four different sizes.
First, the class distribution is displayed for each dataset size. We can see that with a small dataset of 100 examples, we only get one example in the minority class as we might expect. Even with 100,000 examples in the dataset, we only get 1,000 examples in the minority class.
Size=100, Ratio=Counter({0: 99, 1: 1})
Size=1000, Ratio=Counter({0: 990, 1: 10})
Size=10000, Ratio=Counter({0: 9900, 1: 100})
Size=100000, Ratio=Counter({0: 99000, 1: 1000})
Scatter plots are created for each differently sized dataset.
We can see that it is not until very large sample sizes that the underlying structure of the class distributions becomes obvious.
These plots highlight the critical role that dataset size plays in imbalanced classification. It is hard to see how a model given 990 examples of the majority class and 10 of the minority class could hope to do well on the same problem depicted after 100,000 examples are drawn.
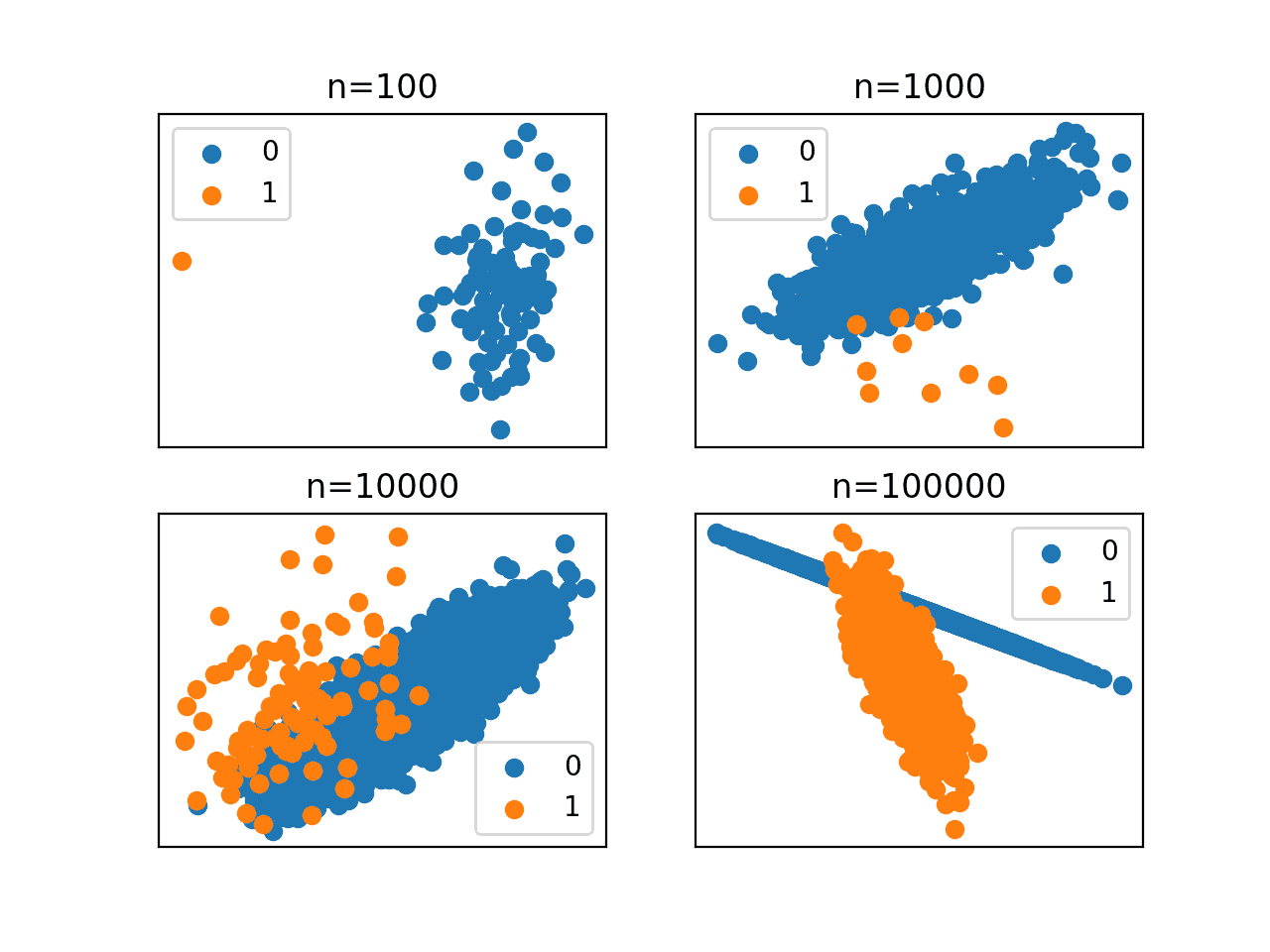
Scatter Plots of an Imbalanced Classification Dataset With Different Dataset Sizes
Compounding Effect of Label Noise
Label noise refers to examples that belong to one class that are assigned to another class.
This can make determining the class boundary in feature space problematic for most machine learning algorithms, and this difficulty typically increases in proportion to the percentage of noise in the labels.
Two types of noise are distinguished in the literature: feature (or attribute) and class noise. Class noise is generally assumed to be more harmful than attribute noise in ML […] class noise somehow affects the observed class values (e.g., by somehow flipping the label of a minority class instance to the majority class label).
— Page 264, Learning from Imbalanced Data Sets, 2018.
The cause is often inherent in the problem domain, such as ambiguous observations on the class boundary or even errors in the data collection that could impact observations anywhere in the feature space.
For imbalanced classification, noisy labels have an even more dramatic effect.
Given that examples in the positive class are so few, losing some to noise reduces the amount of information available about the minorty class.
Additionally, having examples from the majority class incorrectly marked as belonging to the minority class can cause a disjoint or fragmentation of the minority class that is already sparse because of the lack of observations.
We can imagine that if there are examples along the class boundary that are ambiguous, we could identify and remove or correct them. Examples marked for the minority class that are in areas of the feature space that are high density for the majority class are also likely easy to identify and remove or correct.
It is the case where observations for both classes are sparse in the feature space where this problem becomes particularly difficult in general, and especially for imbalanced classification. It is these situations where unmodified machine learning algorithms will define the class boundary in favor of the majority class at the expense of the minority class.
Mislabeled minority class instances will contribute to increase the perceived imbalance ratio, as well as introduce mislabeled noisy instances inside the class region of the minority class. On the other hand, mislabeled majority class instances may lead the learning algorithm, or imbalanced treatment methods, focus on wrong areas of input space.
— Page 264, Learning from Imbalanced Data Sets, 2018.
We can develop an example to give a flavor of this challenge.
We can hold the dataset size constant as well as the 1:100 class ratio and vary the amount of label noise. This can be achieved by setting the “flip_y” argument to the make_classification() function which is a percentage of the number of examples in each class to change or flip the label.
We will explore varying this from 0 percent, 1 percent, 5 percent, and 7 percent.
The complete example is listed below.
# vary the label noise for a 1:100 imbalanced dataset
from collections import Counter
from sklearn.datasets import make_classification
from matplotlib import pyplot
from numpy import where
# label noise ratios
noise = [0, 0.01, 0.05, 0.07]
# create and plot a dataset with different label noise
for i in range(len(noise)):
# determine the label noise
n = noise[i]
# create the dataset
X, y = make_classification(n_samples=1000, n_features=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.99], flip_y=n, random_state=1)
# summarize class distribution
counter = Counter(y)
print('Noise=%d%%, Ratio=%s' % (int(n*100), counter))
# define subplot
pyplot.subplot(2, 2, 1+i)
pyplot.title('noise=%d%%' % int(n*100))
pyplot.xticks([])
pyplot.yticks([])
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
# show the figure
pyplot.show()
Running the example creates and plots the same dataset with a 1:100 class distribution using four different amounts of label noise.
First, the class distribution is printed for each dataset with differing amounts of label noise. We can see that, as we might expect, as the noise is increased, the number of examples in the minority class is increased, most of which are incorrectly labeled.
We might expect these additional 30 examples in the minority class with 7 percent label noise to be quite damaging to a model trying to define a crisp class boundary in the feature space.
Noise=0%, Ratio=Counter({0: 990, 1: 10})
Noise=1%, Ratio=Counter({0: 983, 1: 17})
Noise=5%, Ratio=Counter({0: 963, 1: 37})
Noise=7%, Ratio=Counter({0: 959, 1: 41})
Scatter plots are created for each dataset with the differing label noise.
In this specific case, we don’t see many examples of confusion on the class boundary. Instead, we can see that as the label noise is increased, the number of examples in the mass of the minority class (orange points in the blue area) increases, representing false positives that really should be identified and removed from the dataset prior to modeling.
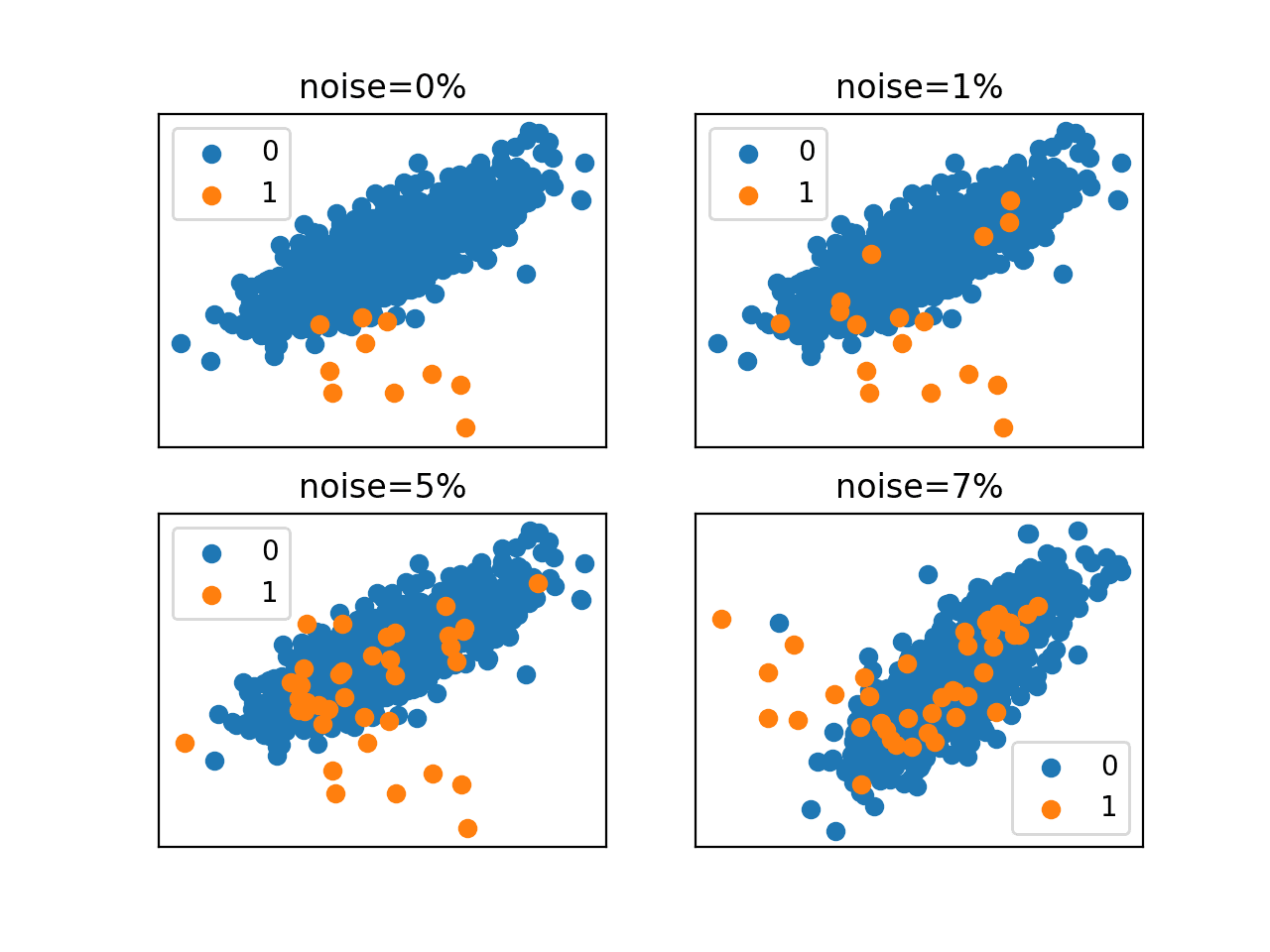
Scatter Plots of an Imbalanced Classification Dataset With Different Label Noise
Compounding Effect of Data Distribution
Another important consideration is the distribution of examples in feature space.
If we think about feature space spatially, we might like all examples in one class to be located on one part of the space, and those from the other class to appear in another part of the space.
If this is the case, we have good class separability and machine learning models can draw crisp class boundaries and achieve good classification performance. This holds on datasets with a balanced or imbalanced class distribution.
This is rarely the case, and it is more likely that each class has multiple “concepts” resulting in multiple different groups or clusters of examples in feature space.
… it is common that the “concept” beneath a class is split into several sub-concepts, spread over the input space.
— Page 255, Learning from Imbalanced Data Sets, 2018.
These groups are formally referred to as “disjuncts,” coming from a definition in the of rule-based systems for a rule that covers a group of cases comprised of sub-concepts. A small disjunct is one that relates or “covers” few examples in the training dataset.
Systems that learn from examples do not usually succeed in creating a purely conjunctive definition for each concept. Instead, they create a definition that consists of several disjuncts, where each disjunct is a conjunctive definition of a subconcept of the original concept.
— Concept Learning And The Problem Of Small Disjuncts, 1989.
This grouping makes class separability hard, requiring each group or cluster to be identified and included in the definition of the class boundary, implicitly or explicitly.
In the case of imbalanced datasets, this is a particular problem if the minority class has multiple concepts or clusters in the feature space. This is because the density of examples in this class is already sparse and it is difficult to discern separate groupings with so few examples. It may look like one large sparse grouping.
This lack of homogeneity is particularly problematic in algorithms based on the strategy of dividing-and-conquering […] where the sub-concepts lead to the creation of small disjuncts.
— Page 255, Learning from Imbalanced Data Sets, 2018.
For example, we might consider data that describes whether a patient is healthy (majority class) or sick (minority class). The data may capture many different types of illnesses, and there may be groups of similar illnesses, but if there are so few cases, then any grouping or concepts within the class may not be apparent and may look like a diffuse set mixed in with healthy cases.
To make this concrete, we can look at an example.
We can use the number of clusters in the dataset as a proxy for “concepts” and compare a dataset with one cluster of examples per class to a second dataset with two clusters per class.
This can be achieved by varying the “n_clusters_per_class” argument for the make_classification() function used to create the dataset.
We would expect that in an imbalanced dataset, such as a 1:100 class distribution, that the increase in the number of clusters is obvious for the majority class, but not so for the minority class.
The complete example is listed below.
# vary the number of clusters for a 1:100 imbalanced dataset
from collections import Counter
from sklearn.datasets import make_classification
from matplotlib import pyplot
from numpy import where
# number of clusters
clusters = [1, 2]
# create and plot a dataset with different numbers of clusters
for i in range(len(clusters)):
c = clusters[i]
# define dataset
X, y = make_classification(n_samples=10000, n_features=2, n_redundant=0,
n_clusters_per_class=c, weights=[0.99], flip_y=0, random_state=1)
counter = Counter(y)
# define subplot
pyplot.subplot(1, 2, 1+i)
pyplot.title('Clusters=%d' % c)
pyplot.xticks([])
pyplot.yticks([])
# scatter plot of examples by class label
for label, _ in counter.items():
row_ix = where(y == label)[0]
pyplot.scatter(X[row_ix, 0], X[row_ix, 1], label=str(label))
pyplot.legend()
# show the figure
pyplot.show()
Running the example creates and plots the same dataset with a 1:100 class distribution using two different numbers of clusters.
In the first scatter plot (left), we can see one cluster per class. The majority class (blue) quite clearly has one cluster, whereas the structure of the minority class (orange) is less obvious. In the second plot (right), we can again clearly see that the majority class has two clusters, and again the structure of the minority class (orange) is diffuse and it is not apparent that samples were drawn from two clusters.
This highlights the relationship between the size of the dataset and its ability to expose the underlying density or distribution of examples in the minority class. With so few examples, generalization by machine learning models is challenging, if not very problematic.
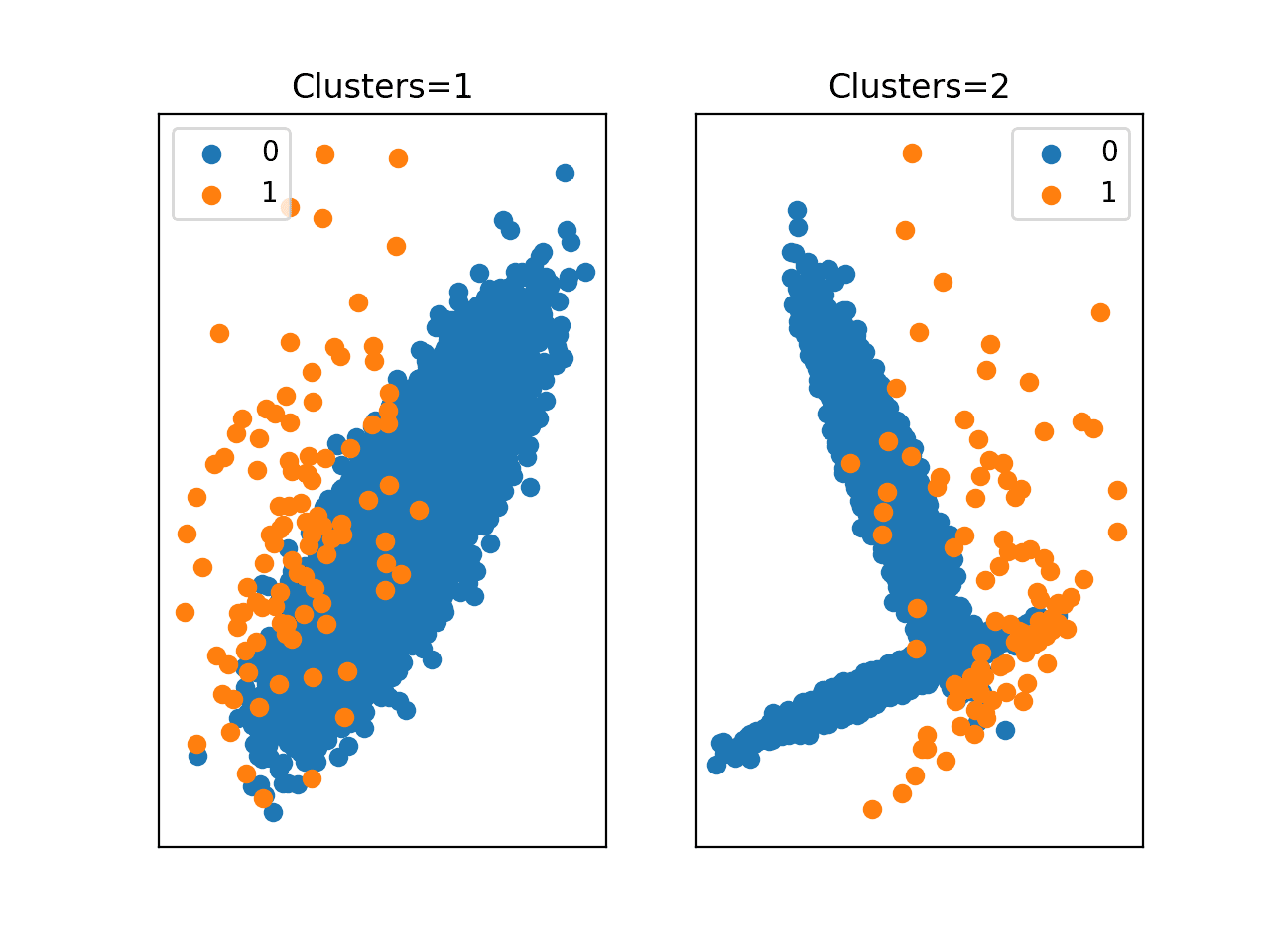
Scatter Plots of an Imbalanced Classification Dataset With Different Numbers of Clusters
Further Reading
This section provides more resources on the topic if you are looking to go deeper.
Papers
Books
- Learning from Imbalanced Data Sets, 2018.
- Imbalanced Learning: Foundations, Algorithms, and Applications, 2013.
APIs
Summary
In this tutorial, you discovered data characteristics that compound the challenge of imbalanced classification.
Specifically, you learned:
- Imbalanced classification is specifically hard because of the severely skewed class distribution and the unequal misclassification costs.
- The difficulty of imbalanced classification is compounded by properties such as dataset size, label noise, and data distribution.
- How to develop an intuition for the compounding effects on modeling difficulty posed by different dataset properties.
Do you have any questions?
Ask your questions in the comments below and I will do my best to answer.
The post Why Is Imbalanced Classification Difficult? appeared first on Machine Learning Mastery.
Ai
via https://www.AiUpNow.com
February 16, 2020 at 01:15PM by Jason Brownlee, Khareem Sudlow

