No, your website’s own search results pages should not be indexed by Google and other search engines in most cases.
Long-standing search-engine-optimization wisdom says the results pages from your site-search should block search engine bots and not be included in a search engine’s index of pages.
The rationale is to avoid disappointing Google’s users and to otherwise prevent search-engine crawlers from wasting their time downloading and analyzing pages that presumably won’t help visitors or your business.
User Experience
Search engines want to provide their users with a good search experience. That is why Google, Bing, and DuckDuckGo, as examples, spend so much time trying to get search results right.
Unfortunately, a search results page from your site may not be a good, relevant result.
Here is an example. Imagine a person goes to Google and types “what is the best running shoe for heavy runners.”
Among the results displayed is one from your site’s internal search results. But the page indexed and linked is a list of products for the search term “men’s running shoes.”
This internal search results page also has a section promoting one of your company’s blog posts. It is that blog post that mentions heavy runners and is somehow indexed.

This internal search results page would not be a great landing page, and probably should not be included in the index.
This result is not helpful. The person using the search engine has to click twice — once on Google’s search results and once on your site’s internal results — to get to the information he needs. Moreover, the visitor might misinterpret the result and assume your site is showing him a list of cushioned running shoes only to be disappointed after placing an order.
A worse example comes from a 2018 article by Matt Tutt, a U.K.-based technical SEO expert.
In the article, Tutt noted that online retailer Wayfair was allowing some of its dynamically-generated search results pages to be indexed.
If you searched Google at the time of Tutt’s article for “Wayfair.com” with a certain sex-related phrase, you would see a result.
Wayfair was dynamically adding keywords to its search page descriptions, so the copy you would see on Google’s SERP read, “Shop Wayfair for the best [sex-related word]. Enjoy free shipping on most stuff, even big stuff.”
“If you were brave enough to click through the above SERP you’d be greeted by” the following copy, according to Tutt.
“[Sex-related word]. At Wayfair, we want to make sure you find the best home goods when you shop online. You have searched for [sex-related word] and this page displays the closest product matches…”
As Tutt notes, this page and its copy “isn’t the kind of content you’d want users or search engines to discover as a home furniture provider.”
In other words, many internal search results pages are automatically generated and may not be good content for users searching on Google or another search engine.
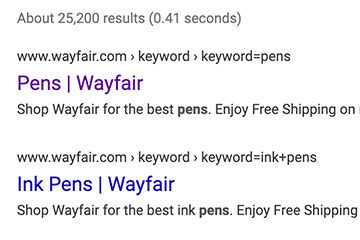
Wayfair has since changed its search results so that a search for this particular keyword now returns “pens” on the Wayfair site rather than the original sex term.
Allowing dynamic pages to be indexed means not knowing what sorts of results your company is showing to potential customers.
This is not much better. Google probably doesn’t want to rank your company’s internal search results pages, and you’re wasting a lot of Googlebot’s energy, if you will, on pages that may not do your company much good.
Lost in the Weeds
“For internal search pages, there are two aspects that play a role for us,” said Google’s John Mueller during an April 2018 Webmaster Central Hangout.
“One is that it is very easy for us to get lost in the weeds by trying to crawl all of your internal search pages. If basically any word on your site could lead to an internal search page, and we have all of these potential internal search pages, and they all serve content, then our systems might go off and say, ‘Oh, we will try to crawl all of your internal search pages because maybe there is something really useful there.’ So from a crawling point of view, that is probably not that optimal.”
Googlebot allocates time — the “crawl budget” — for each site. There are presumably better pages on your website to crawl other than internal search results.
One Exception
Tutt, Mueller, and others do mention that there is probably one exception to the rule: If you use your site’s internal search results for category pages.
Advanced search platforms — e.g., Twiggle, Algolia — can generate product category or brand pages. A merchant could configure the platform with synonyms and antonyms to deliver or exclude a category.
Blocking Search Engines
There are at least two ways to tell Google and other search engines not to index your site’s internal search results pages: the noindex directive in the head section of each page and the disallow rule in a robots.txt file. (I addressed that topic “SEO: Tell Google Which Pages Not to Crawl.”)
Having addressed why merchants should block internal search results pages from being indexed, I then reviewed how 10 leading ecommerce sites were doing it. On March 9, 2020, I checked each site’s robots.txt file for a disallow rule and, also, reviewed site-search results for the noindex directive.
| Site | Robots.txt disallow | noindex |
|---|---|---|
| Amazon | No | No |
| Barnes & Noble | Yes | Yes |
| Bath & Body Works | Yes | No |
| Best Buy | No | No |
| GameStop | Yes | Yes |
| Home Depot | Yes | No |
| Lands' End | Yes | No |
| Sur La Table | Yes | Yes |
| Target | Yes | Yes |
| Walmart | Yes | No |
I chose Amazon, Walmart, and Target due to their prominence. The other seven I picked more or less at random from a list of ecommerce sites that I follow. Only two of the 10 sites blocked search engines from indexing internal search results pages.
March 10, 2020 at 09:03AM
via https//www.brucedayne.com/
Armando Roggio, Khareem Sudlow

