Model Training Can Be Slow
In deep learning, using more compute (e.g., increasing model size, dataset size, or training steps) often leads to higher accuracy. This is especially true given the recent success of unsupervised pretraining methods like BERT, which can scale up training to very large models and datasets. Unfortunately, large-scale training is very computationally expensive, especially without the hardware resources of large industry research labs. Thus, the goal in practice is usually to get high accuracy without exceeding one’s hardware budget and training time.
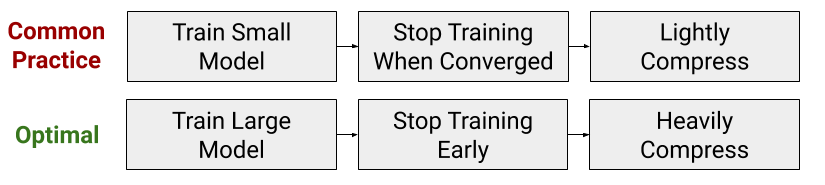
For most training budgets, very large models appear impractical. Instead, the go-to strategy for maximizing training efficiency is to use models with small hidden sizes or few layers because these models run faster and use less memory.
Larger Models Train Faster
However, in our recent paper, we show that this common practice of reducing model size is actually the opposite of the best compute-efficient training strategy. Instead, when training Transformer models on a budget, you want to drastically increase model size but stop training very early. In other words, we rethink the implicit assumption that models must be trained until convergence by demonstrating the opportunity to increase model size while sacrificing convergence.
This phenomenon occurs because larger models converge to lower test error in fewer gradient updates than smaller models. Moreover, this increase in convergence outpaces the extra computational cost of using larger models. Consequently, when considering wall-clock training time, larger models achieve higher accuracy faster.
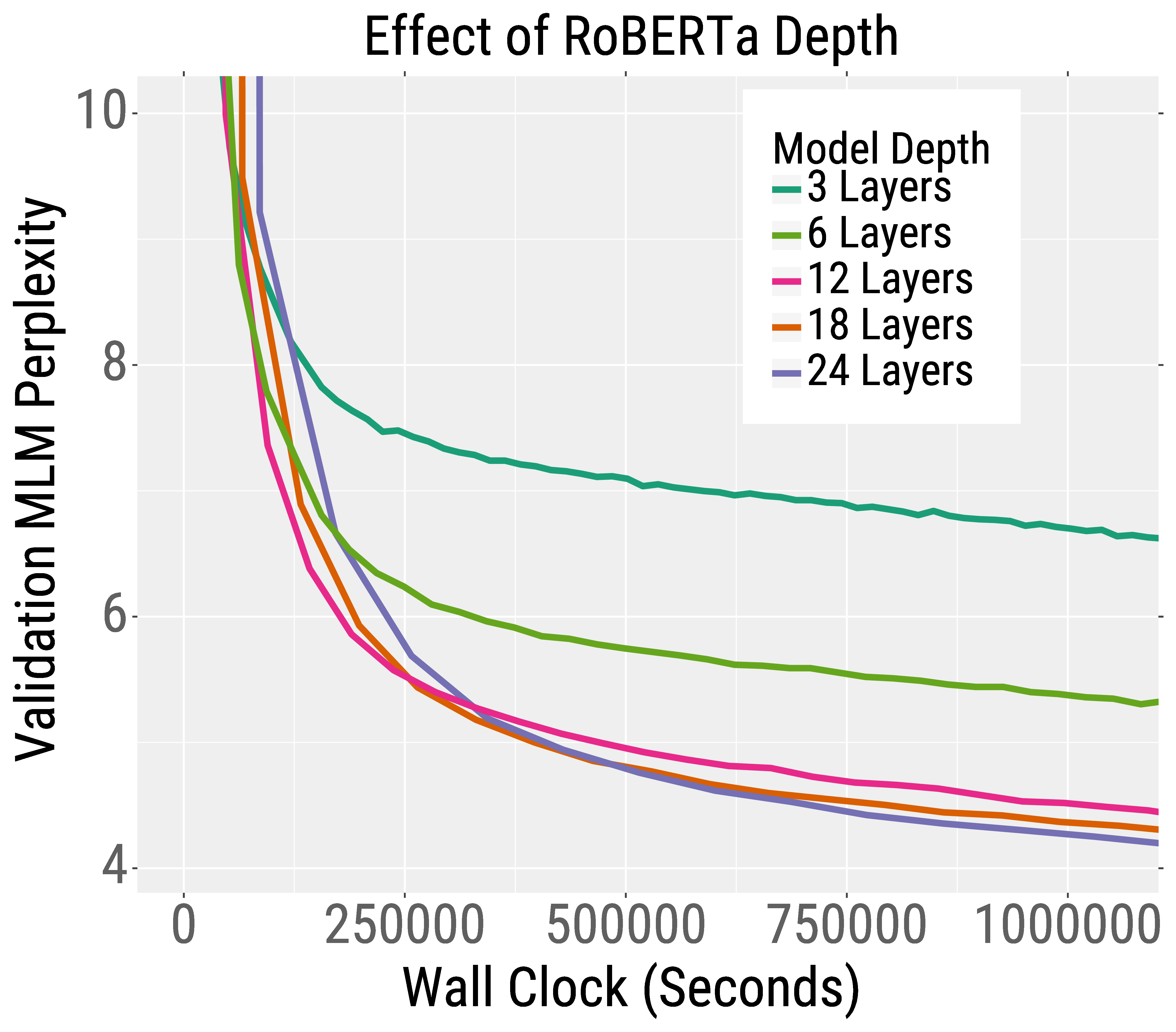
We demonstrate this trend in the two training curves below. On the left, we plot the validation error for pretraining RoBERTa, a variant of BERT. The deeper RoBERTa models achieve lower perplexity than the shallower models for a given wall clock time (our paper shows the same is true for wider models). This trend also holds for machine translation. On the right, we plot the validation BLEU score (higher is better) when training an English-French Transformer machine translation model. The deeper and wider models achieve higher BLEU score than smaller models given the same training time.
![]()
Interestingly, for pretraining RoBERTa, increasing model width and/or depth both lead to faster training. For machine translation, wider models outperform deeper models. We thus recommend to try increasing width before going deeper.
We also recommend increasing model size, not batch size. Concretely, we confirm that once the batch size is near a critical range, increasing the batch size only provides marginal improvements in wall-clock training time. Thus, when under resource constraints, we recommend to use a batch size inside this critical region and then to use larger model sizes.
But What About Test Time?
Although larger models are more training-efficient, they also increase the computational and memory requirements of inference. This is problematic because the total cost of inference is much larger than the cost of training for most real-world applications. However, for RoBERTa, we show that this trade-off can be reconciled with model compression. In particular, larger models are more robust to model compression techniques than small models. Thus, one can get the best of both worlds by training very large models and then heavily compressing them.
We use the compression methods of quantization and pruning. Quantization stores model weights in low precision formats; pruning sets certain neural network weights to zero. Both methods can reduce the inference latency and memory requirements of storing model weights.
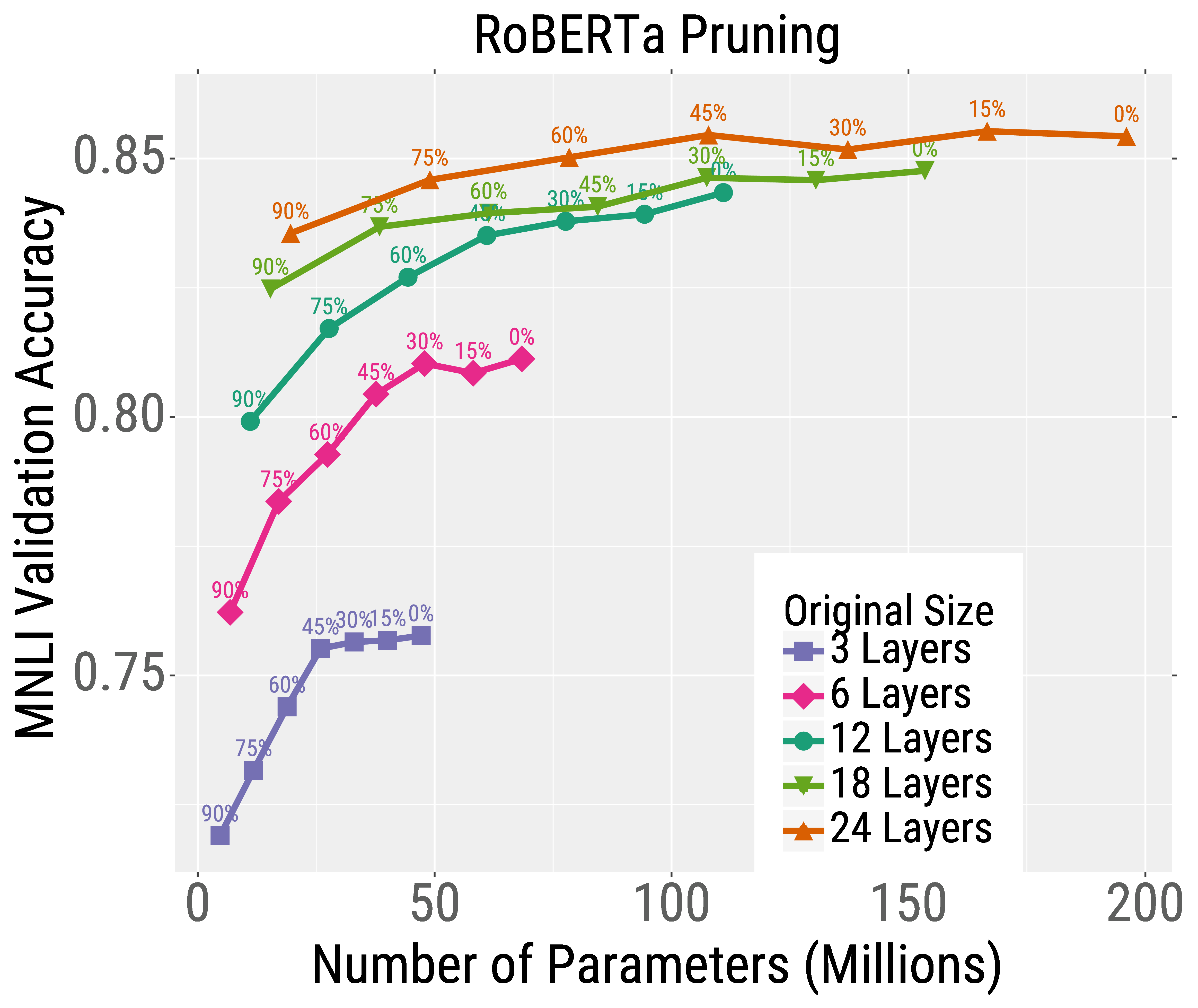
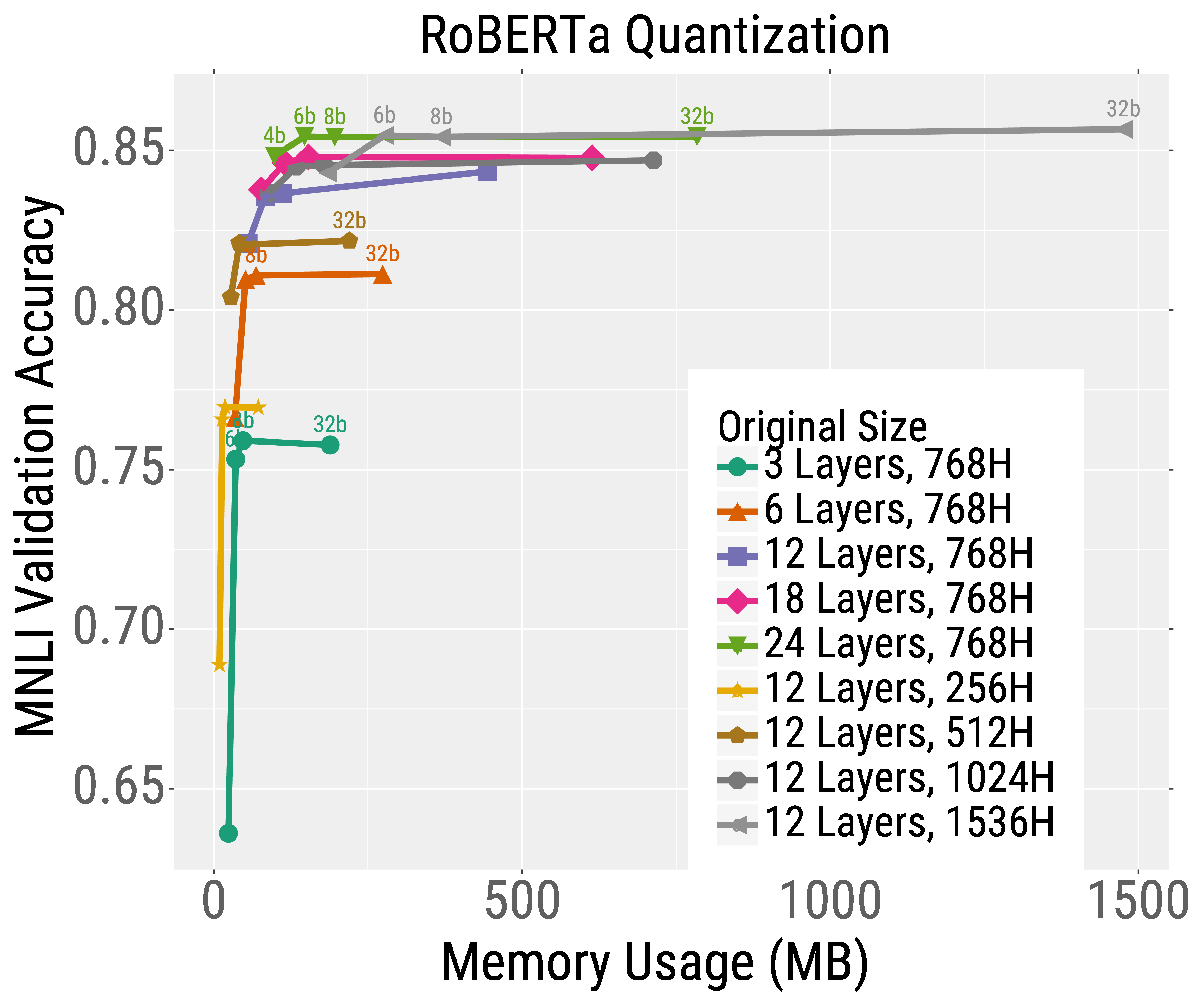
We first pretrain RoBERTa models of different sizes for the same total wall-clock time. We then finetune these models on a downstream text classification task (MNLI) and apply either pruning or quantization. We find that the best models for a given test-time budget are the models that are trained very large and then heavily compressed.
For example, consider the pruning results for the deepest model (orange curve in the left Figure below). Without pruning the model, it reaches high accuracy but uses about 200 million parameters (and thus lots of memory and compute). However, this model can be heavily pruned (the points moving to the left along the curve) without considerably hurting accuracy. This is in stark contrast to the smaller models, e.g., the 6 layer model shown in pink, whose accuracy heavily degrades after pruning. A similar trend occurs for quantization (right Figure below). Overall, the best model for most test budgets (pick a point on the x-axis) are the very large but heavily compressed models.
Conclusion
We have shown that increasing Transformer model size can improve the efficiency of training and inference, i.e., one should Train Large, Then Compress. This finding leads to many other interesting questions such as why larger models converge faster and compress better. In our paper, we present initial investigations into this phenomenon, however, future work is still required. Moreover, our findings are currently specific to NLP—we would like to explore how these conclusions generalize to other domains like computer vision.
Contact Eric Wallace on Twitter. Thanks to Zhuohan Li, Kevin Lin, and Sheng Shen and for their feedback on this post.
See our paper “Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers” by Zhuohan Li*, Eric Wallace*, Sheng Shen*, Kevin Lin*, Kurt Keutzer, Dan Klein, and Joseph E. Gonzalez.
Ai
via https://www.AiUpNow.com
March 4, 2020 at 11:47PM by , Khareem Sudlow

