The World is Continuously Varying
Imagine we want to train a self-driving car in New York so that we can take it all the way to Seattle without tediously driving it for over 48 hours. We hope our car can handle all kinds of environments on the trip and send us safely to the destination. We know that road conditions and views can be very different. It is intuitive to simply collect road data of this trip, let the car learn from every possible condition, and hope it becomes the perfect self-driving car for our New York to Seattle trip. It needs to understand the traffic and skyscrapers in big cities like New York and Chicago, more unpredictable weather in Seattle, mountains and forests in Montana, and all kinds of country views, farmlands, animals, etc. However, how much data is enough? How many cities should we collect data from? How many weather conditions should we consider? We never know, and these questions never stop.
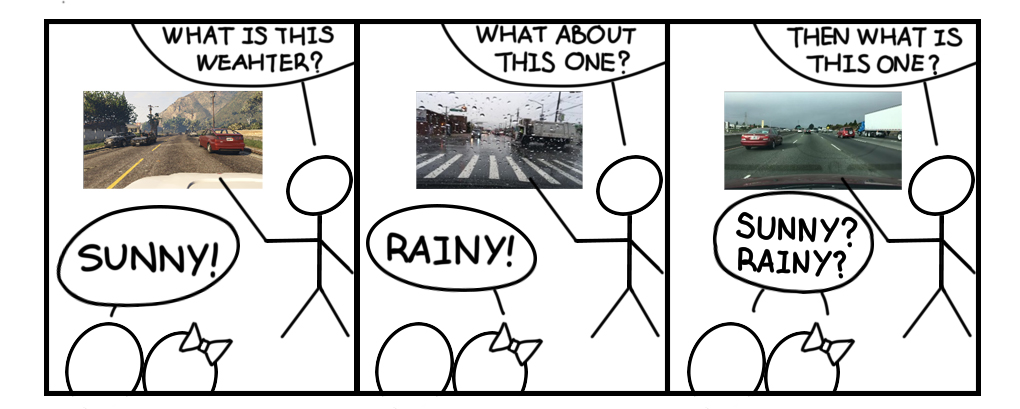
Figure 1: Domains boundaries are rarely clear. Therefore, it is hard to set up definite domain descriptions for all possible domains.
As for the weather, the number of different conditions can be infinite, while the words that can be used to describe weather conditions (such as sunny and rainy) are always limited. Some conditions have subtle differences that even humans can not tell. For example, overcast v.s. cloudy, the transition state of rainy to non-rainy, light snow v.s. light rain, etc. We can always try to collect data for every possible weather condition that we can imagine and use traditional domain adaptation methods to help our car to adapt to these conditions. But our imagination is limited when it comes to weather, and the main reason is that there are no clear boundaries between weather conditions. In that case, none of the traditional domain adaptation approaches, where clear boundaries are assumed, can help us in real-world weather adaption. Therefore, we start rethinking machine learning and domain adaptation systems, and try to introduce a continuous learning protocol under domain adaptation scenario.
Open Compound Domain Adaptation (OCDA)
The goal of domain adaptation is to adapt the model learned on the training data to the test data of a different distribution. Such a distributional gap is often formulated as a shift between discrete concepts of well defined data domains, e.g., images collected in sunny weather versus those in rainy weather. Though domain generalization and latent domain adaptation have attempted to tackle complex target domains, most existing works usually assume that there is a known clear distinction between domains. Such a known and clear distinction between domains is hard to define in practice, e.g., test images could be collected in mixed, continually varying, and sometimes never seen weather conditions. With numerous factors jointly contributing to data variance, it becomes implausible to separate data into discrete domains.
We propose to study Open Compound Domain Adaptation (OCDA), a continuous and more realistic setting for domain adaptation (Figure 2). The task is to learn a model from labeled source domain data and adapt it to unlabeled compound target domain data which could differ from the source domain on various factors. Our target domain can be regarded as a combination of multiple traditionally homogeneous domains where each is distinctive on one or two major factors, and yet none of the domain labels are given. For example, the five well-known datasets on digits recognition (SVHN, MNIST, MNIST-M, USPS, and SynNum) mainly differ from each other by the backgrounds and text fonts. It is not necessarily the best practice, and not feasible under some scenarios, to consider them as distinct domains. Instead, our compound target domain pools them together. Furthermore, at the inference stage, OCDA tests the model not only in the compound target domain but also in open domains that have previously unseen during training.
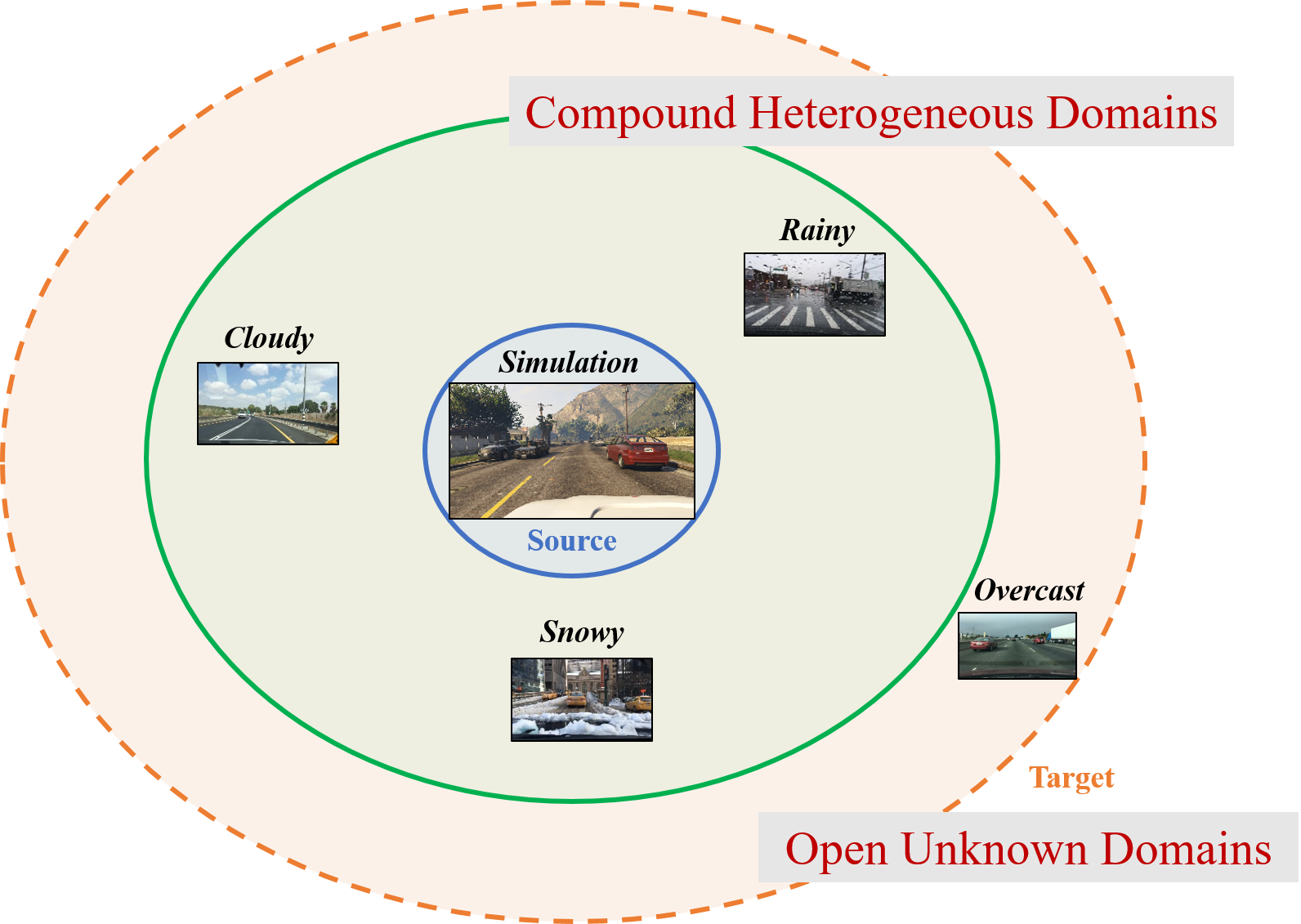
Figure 2: Open Compound Domain Adaptation problem. Unlike existing domain adaptation which assumes clear distinctions between discrete domains, our compound target domain is a combination of multiple traditionally homogeneous domains without any domain labels. We also allow novel domains to show up at the inference time.
While OCDA has not been defined in the literature, there are two closely related tasks which are often studied in isolation: single-target domain adaptation, and multi-target domain adaptation. Figure 3 summarizes their differences. The newly proposed Open Compound Domain Adaptation (OCDA) serves as a more comprehensive and more realistic touchstone for evaluating domain adaptation and transfer learning systems.
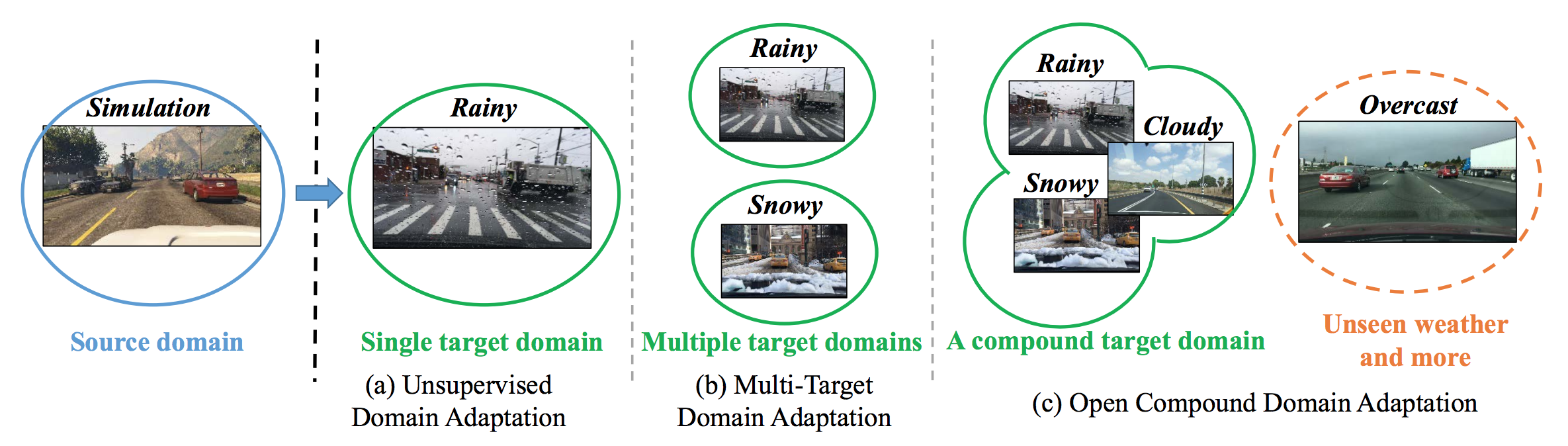
Figure 3: The differences between single-target domain adaptation, multi-target domain adaptation and our open compound domain adaptation (OCDA).
The Importance of Curriculum & Memory
In our OCDA setting, the target domain no longer has a predominantly uni-modal distribution, posing challenges to existing domain adaptation methods. We propose a novel approach based on two technical insights into OCDA: 1) a curriculum domain adaptation strategy to bootstrap generalization across domain distinction in a data-driven self-organizing fashion and 2) a memory module to increase the model’s agility towards novel domains, as illustrated in Figure 4.
Firstly, unlike existing curriculum adaptation methods that rely on some holistic measure of instance difficulty, we schedule the learning of unlabeled instances in the compound target domain according to their individual gaps to the labeled source domain, so that we solve an incrementally harder domain adaptation problem till we cover the entire target domain.
Our second technical insight is to prepare our model for open domains during inference with a memory module that effectively augments the representations of an input for classification. Intuitively, if the input is close enough to the source domain, the feature extracted from itself can most likely already result in accurate classification. Otherwise, the input-activated memory features can step in and play a more important role. Consequently, this memory-augmented network is more agile at handling open domains than its vanilla counterpart.

Figure 4: Overview of our approach. 1) We separate characteristics specific to domains from those discriminative between classes. The teased out domain feature is used to construct a curriculum for domain-robust learning. 2) We enhance our network with a memory module that facilitates knowledge transfer from the source domain to target domain instances, so that the network can dynamically balance the input information and the memory-transferred knowledge for more agility towards previously unseen domains.
Robustness to Compound and Open Domains
We control the complexity of the compound and open target domain by varying the number of traditional target domains / datasets in it. Here we gradually increase constituting domains from a single target domain to two, and eventually three. As demonstrated in Figure 5, we observe that our approach is more resilient to the various numbers of compound and open domains. 1) The learned curriculum enables gradual knowledge transfer that is capable of coping with complex structures in the compound target domain. 2) Furthermore, the domain indicator module in our framework helps dynamically calibrate the embedding, thus enhancing the robustness to open domains.
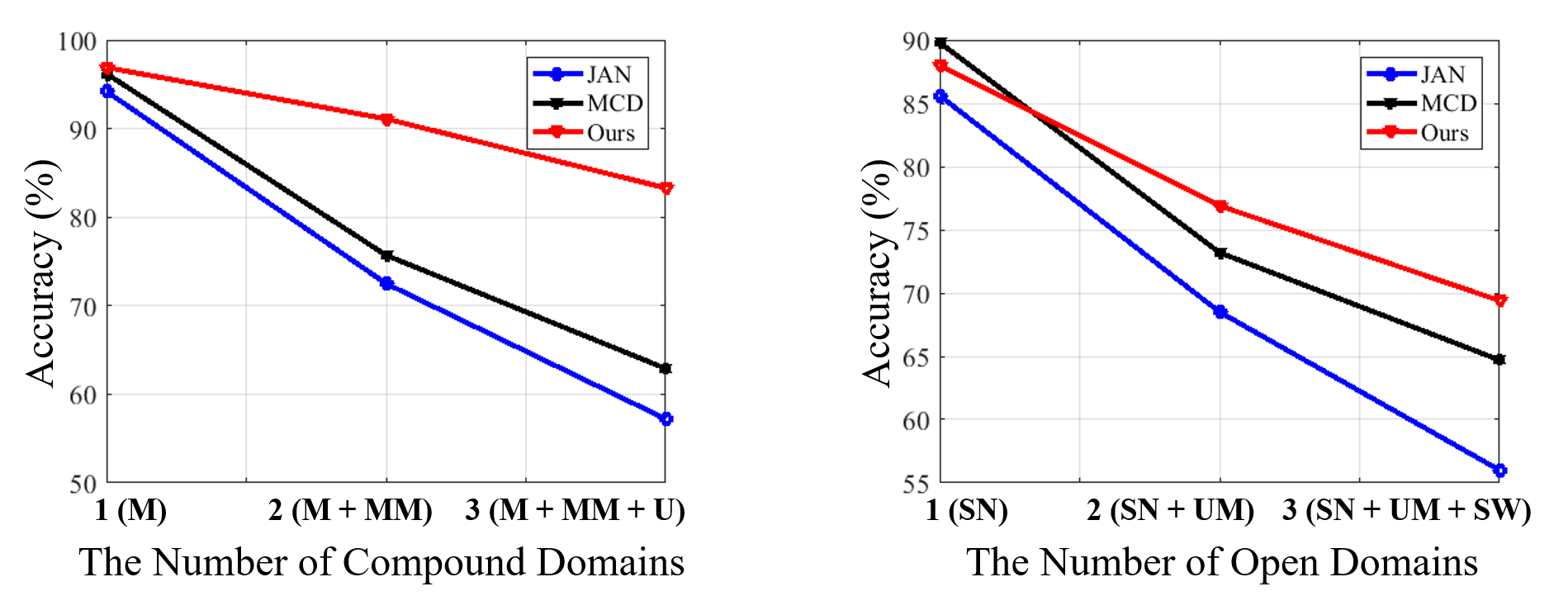
Figure 5: The performance change w.r.t. the number of compound and open domains.
Visualization of Learning Dynamics
Here is a visualization of disentangling domain characteristics. We separate characteristics specific to domains from those discriminative between classes. It is achieved by a class-confusion algorithm in an unsupervised manner. Figure 6 (a) and (b) visualize the examples embedded by the class encoder and domain encoder, respectively. The class encoder places instances in the same class in a cluster, while the domain encoder places instances according to their common appearances, regardless of their classes.
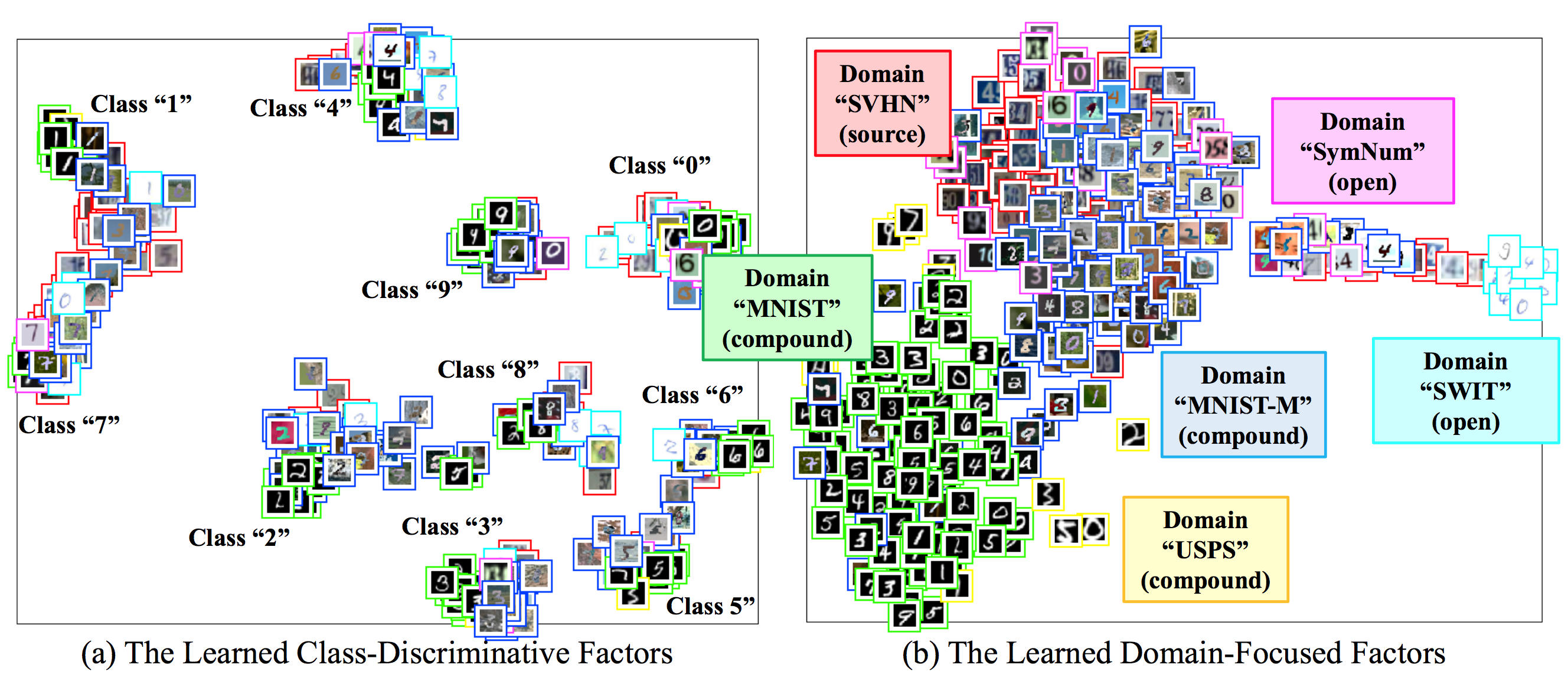
Figure 6: t-SNE Visualization of our (a) class-discriminative features, and (b) domain features. Our framework disentangles the mixed-domain data into class-discriminative factors and domain-focused factors.
Acknowledgements: We thank all co-authors of the paper “Open Compound Domain Adaptation” for their contributions and discussions in preparing this blog. The views and opinions expressed in this blog are solely of the authors of this paper.
This blog post is based on the following paper which will be presented at IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2020) as an oral presentation:
- Open Compound Domain Adaptation
Ziwei Liu*, Zhongqi Miao*, Xingang Pan, Xiaohang Zhan, Dahua Lin, Stella X. Yu, Boqing Gong
Paper, Project Page, Dataset, Code & Model
Ai
via https://www.AiUpNow.com
June 14, 2020 at 03:23PM by , Khareem Sudlow

