
A demonstration of the RvS policy we learn with just supervised learning and a depth-two MLP. It uses no TD learning, advantage reweighting, or Transformers!
Offline reinforcement learning (RL) is conventionally approached using value-based methods based on temporal difference (TD) learning. However, many recent algorithms reframe RL as a supervised learning problem. These algorithms learn conditional policies by conditioning on goal states (Lynch et al., 2019; Ghosh et al., 2021), reward-to-go (Kumar et al., 2019; Chen et al., 2021), or language descriptions of the task (Lynch and Sermanet, 2021).
We find the simplicity of these methods quite appealing. If supervised learning is enough to solve RL problems, then offline RL could become widely accessible and (relatively) easy to implement. Whereas TD learning must delicately balance an actor policy with an ensemble of critics, these supervised learning methods train just one (conditional) policy, and nothing else!
So, how can we use these methods to effectively solve offline RL problems? Prior work puts forward a number of clever tips and tricks, but these tricks are sometimes contradictory, making it challenging for practitioners to figure out how to successfully apply these methods. For example, RCPs (Kumar et al., 2019) require carefully reweighting the training data, GCSL (Ghosh et al., 2021) requires iterative, online data collection, and Decision Transformer (Chen et al., 2021) uses a Transformer sequence model as the policy network.
Which, if any, of these hypotheses are correct? Do we need to reweight our training data based on estimated advantages? Are Transformers necessary to get a high-performing policy? Are there other critical design decisions that have been left out of prior work?
Our work aims to answer these questions by trying to identify the essential elements of offline RL via supervised learning. We run experiments across 4 suites, 26 environments, and 8 algorithms. When the dust settles, we get competitive performance in every environment suite we consider using remarkably simple elements. The video above shows the complex behavior we learn using just supervised learning with a depth-two MLP – no TD learning, data reweighting, or Transformers!
RL via Supervised Learning
Let’s begin with an overview of the algorithm we study. While lots of prior work (Kumar et al., 2019; Ghosh et al., 2021; and Chen et al., 2021) share the same core algorithm, it lacks a common name. To fill this gap, we propose the term RL via Supervised Learning (RvS). We are not proposing any new algorithm but rather showing how prior work can be viewed from a unifying framework; see Figure 1.
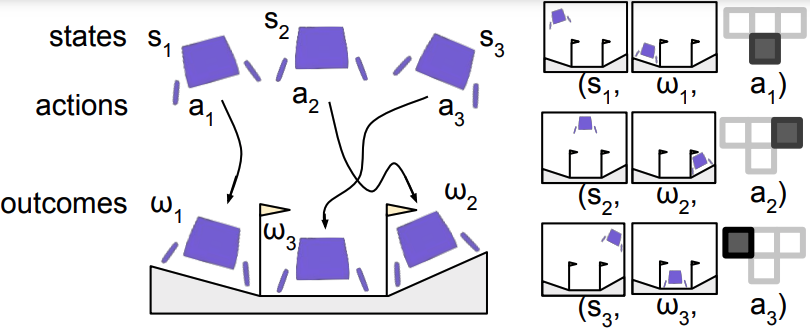
Figure 1. (Left) A replay buffer of experience (Right) Hindsight relabelled training data
RL via Supervised Learning takes as input a replay buffer of experience including states, actions, and outcomes. The outcomes can be an arbitrary function of the trajectory, including a goal state, reward-to-go, or language description. Then, RvS performs hindsight relabeling to generate a dataset of state, action, and outcome triplets. The intuition is that the actions that are observed provide supervision for the outcomes that are reached. With this training dataset, RvS performs supervised learning by maximizing the likelihood of the actions given the states and outcomes. This yields a conditional policy that can condition on arbitrary outcomes at test time.
Experimental Results
In our experiments, we focus on the following three key questions.
- Which design decisions are critical for RL via supervised learning?
- How well does RL via supervised learning actually work? We can do RL via supervised learning, but would using a different offline RL algorithm perform better?
- What type of outcome variable should we condition on? (And does it even matter?)
Network Architecture
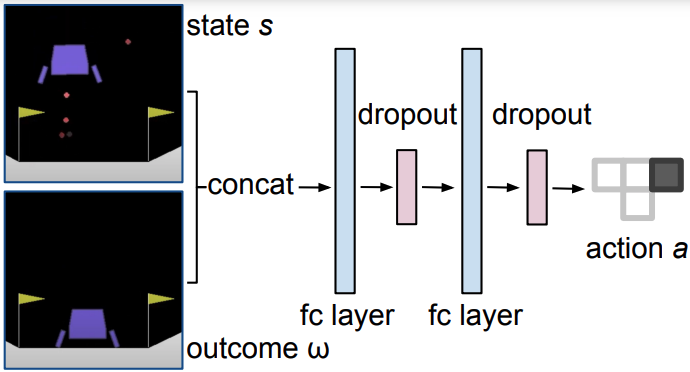
Figure 2. Our RvS architecture. A depth-two MLP suffices in every environment suite we consider.
We get good performance using just a depth-two multi-layer perceptron. In fact, this is competitive with all previously published architectures we’re aware of, including a Transformer sequence model. We just concatenate the state and outcome before passing them through two fully-connected layers (see Figure 2). The keys that we identify are having a network with large capacity – we use width 1024 – as well as dropout in some environments. We find that this works well without reweighting the training data or performing any additional regularization.
Overall Performance
After identifying these key design decisions, we study the overall performance of RvS in comparison to previous methods. This blog post will overview results from two of the suites we consider in the paper.
D4RL Gym
 The first suite is D4RL Gym, which contains the standard MuJoCo halfcheetah, hopper, and walker robots. The challenge in D4RL Gym is to learn locomotion policies from offline datasets of varying quality. For example, one offline dataset contains rollouts from a totally random policy. Another dataset contains rollouts from a “medium” policy trained partway to convergence, while another dataset is a mixture of rollouts from medium and expert policies.
The first suite is D4RL Gym, which contains the standard MuJoCo halfcheetah, hopper, and walker robots. The challenge in D4RL Gym is to learn locomotion policies from offline datasets of varying quality. For example, one offline dataset contains rollouts from a totally random policy. Another dataset contains rollouts from a “medium” policy trained partway to convergence, while another dataset is a mixture of rollouts from medium and expert policies.
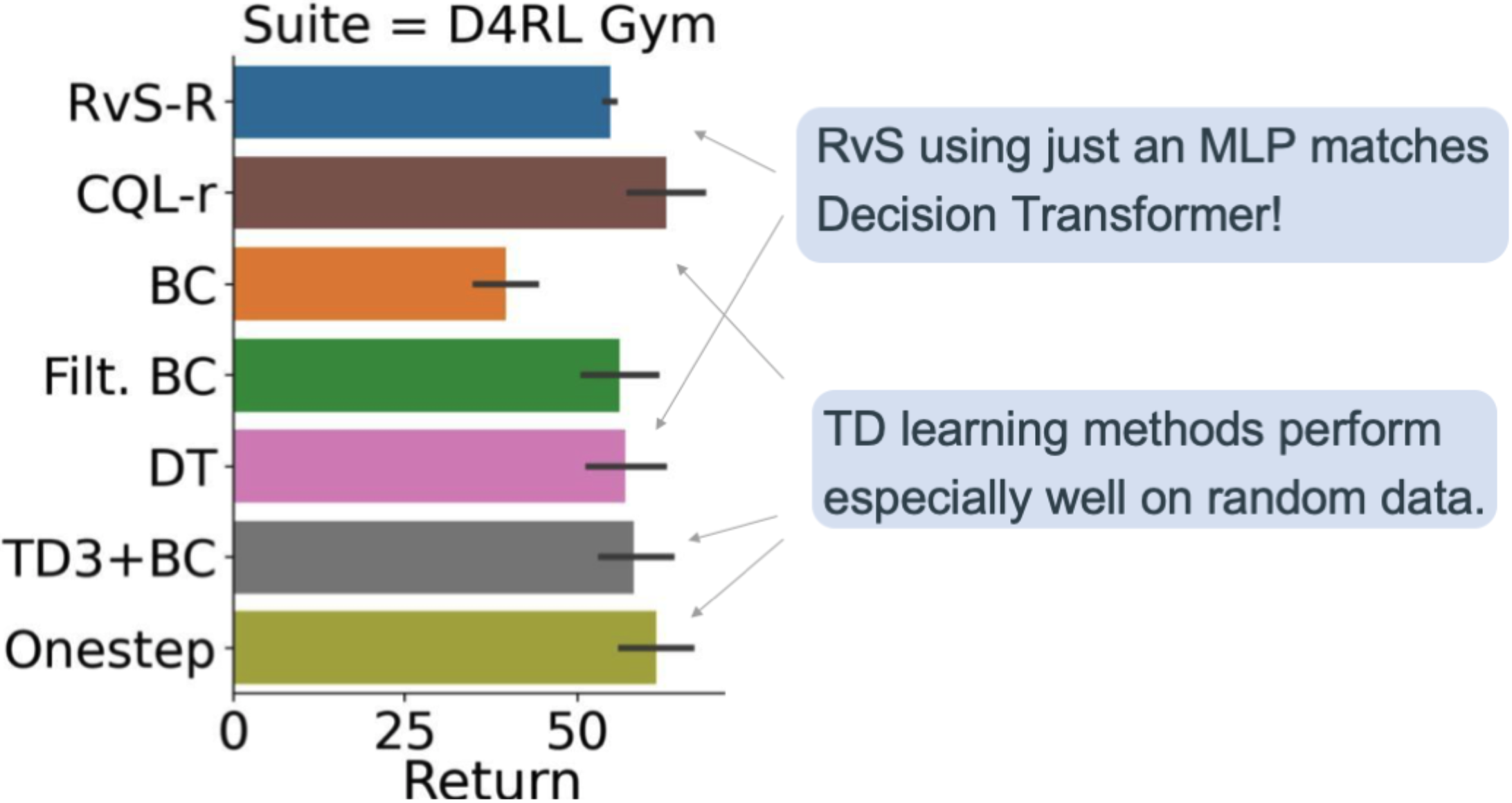
Figure 3. Overall performance in D4RL Gym.
Figure 3 shows our results in D4RL Gym. RvS-R is our implementation of RvS conditioned on rewards (illustrated in Figure 2). On average across all 12 tasks in the suite, we see that RvS-R, which uses just a depth-two MLP, is competitive with Decision Transformer (DT; Chen et al., 2021). We also see that RvS-R is competitive with the methods that use temporal difference (TD) learning, including CQL-R (Kumar et al., 2020), TD3+BC (Fujimoto et al., 2021), and Onestep (Brandfonbrener et al., 2021). However, the TD learning methods have an edge because they perform especially well on the random datasets. This suggests that one might prefer TD learning over RvS when dealing with low-quality data.
D4RL AntMaze
 The second suite is D4RL AntMaze. This suite requires a quadruped to navigate to a target location in mazes of varying size. The challenge of AntMaze is that many trajectories contain only pieces of the full path from the start to the goal location. Learning from these trajectories requires stitching together these pieces to get the full, successful path.
The second suite is D4RL AntMaze. This suite requires a quadruped to navigate to a target location in mazes of varying size. The challenge of AntMaze is that many trajectories contain only pieces of the full path from the start to the goal location. Learning from these trajectories requires stitching together these pieces to get the full, successful path.
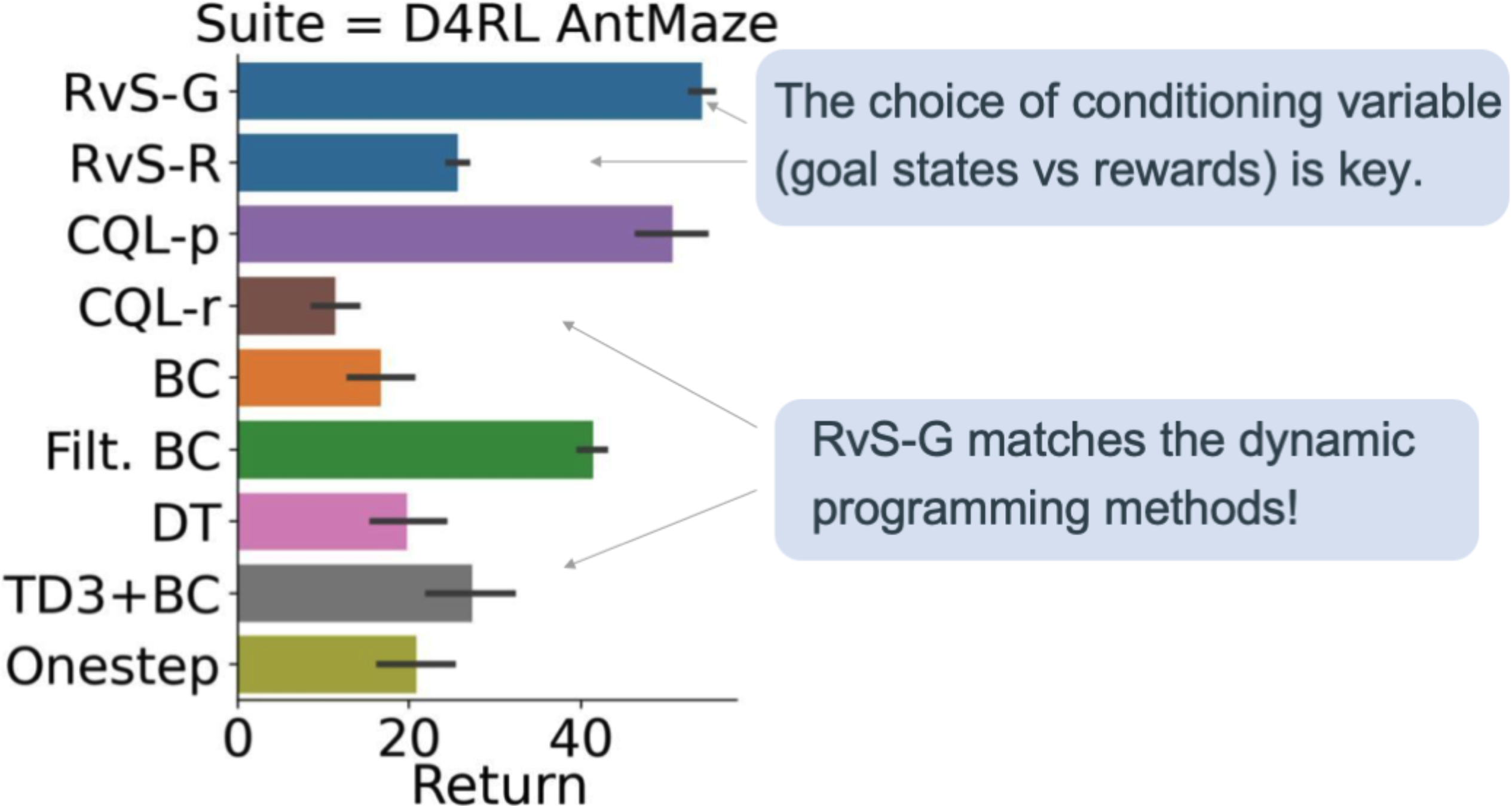
Figure 4. Overall performance in D4RL AntMaze.
Our AntMaze results in Figure 4 highlight the importance of the conditioning variable. Whereas conditioning RvS on rewards (RvS-R) was the best choice of the conditioning variable in D4RL Gym, we find that in D4RL AntMaze, it is much better to condition RvS on $(x, y)$ goal coordinates (RvS-G). When we do this, we see that RvS-G compares favorably to TD learning! This was surprising to us because TD learning explicitly performs dynamic programming using the Bellman equation.
Why does goal-conditioning perform better than reward conditioning in this setting? Recall that AntMaze is designed so that simple imitation is not enough: optimal methods must stitch together parts of suboptimal trajectories to figure out how to reach the goal. In principle, TD learning can solve this with temporal compositionality. With the Bellman equation, TD learning can combine a path from A to B with a path from B to C, yielding a path from A to C. RvS-R, along with other behavior cloning methods, does not benefit from this temporal compositionality. We hypothesize that RvS-G, on the other hand, benefits from spatial compositionality. This is because, in AntMaze, the policy needed to reach one goal is similar to the policy needed to reach a nearby goal. We see correspondingly that RvS-G beats RvS-R.
Of course, conditioning RvS-G on $(x, y)$ coordinates represents a form of prior knowledge about the task. But this also highlights an important consideration for RvS methods: the choice of conditioning information is critically important, and it may depend significantly on the task.
Conclusion
Overall, we find that in a diverse set of environments, RvS works well without needing any fancy algorithmic tricks (such as data reweighting) or fancy architectures (such as Transformers). Indeed, our simple RvS setup can match, and even outperform, methods that utilize (conservative) TD learning. The keys for RvS that we identify are model capacity, regularization, and the conditioning variable.
In our work, we handcraft the conditioning variable, such as $(x, y)$ coordinates in AntMaze. Beyond the standard offline RL setup, this introduces an additional assumption, namely, that we have some prior information about the structure of the task. We think an exciting direction for future work would be to remove this assumption by automating the learning of the goal space.
Reproducing Experiments
We packaged our open-source code so that it can automatically handle all the dependencies for you. After downloading the code, you can run these five commands to reproduce our experiments:
docker build -t rvs:latest .
docker run -it --rm -v $(pwd):/rvs rvs:latest bash
cd rvs
pip install -e .
bash experiments/launch_gym_rvs_r.sh
This post is based on the paper:
RvS: What is Essential for Offline RL via Supervised Learning?
Scott Emmons, Benjamin Eysenbach, Ilya Kostrikov, Sergey Levine
International Conference on Learning Representations (ICLR), 2022
[Paper] [Code]
via https://AIupNow.com
, Khareem Sudlow

