Recently, Microsoft Research published the LASER method: ”Layer-Selective Rank Reduction” in this recent, very popular paper
The Truth is in There: Improving Reasoning in Language Models
with Layer-Selective Rank Reduction
And it got a lot of press (the Verge ) because it hints that it may be possible to improve the truthfulness of LLMs with a simple mathematical transformation
The thing is, the weightwatcher tool has had a similar feature for some time, called SVDSmoothing. And like the name sounds, you can apply TruncatedSVD to the layers of an AI model, like an LLM, to improve performance.
Lets take a deep look at how you can apply this yourself, and why it works.
First, it you haven’t done so already, install weightwatcher
pip install weightwatcher
For our example on Google Colab, we will also need the accelerate package
!pip install accelerate
Requirements
- weightwatcher version 0.7.4.7 or higher
- pytroch or keras frameworks (onnx support is available but not well tested)
- your LLM must be loaded into memory *(the SVDSmoothing option does. not support safetensors or related ‘lazy’ formats yet)
- the model must have only Dense / MLP layers *(no LSTM, although Conv2D layers are ok)
An Example: TinyLLaMA
For our example, we will use the TInyLLaMA LLM. Use git to download the model files to a local folder
!git clone https://huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-955k-token-2T/
We will also need a folder to store our smoothed model in for testing later.
We copy the folder, and remove the model files in it:
import os
tinyLLaMA_folder = "TinyLlama-1.1B-intermediate-step-955k-token-2T"
smoothed_model_folder = "smoothed_TinyLLaMA"
smoothed_model_filename = os.path.join(smoothed_model_folder, "pytorch_model.bin")
!cp -r $tinyLLaMA_folder $smoothed_model_folder
!rm $smoothed_model_filename
Running SVDSmoothing with WeightWatcher
We first need to load the model into memory. (for now; later a version can be made that supports the safetensors format, reducing the memory footprint considerably)
import torch
tinyLLaMA_filename = os.path.join(tinyLLaMA_folder, "pytorch_model.bin")
tinyLLaMA = torch.load(tinyLLaMA_filename)
Getting Started: Describe a model
Before we run this, however, lets first check that weightwatcher is working properly by running watcher.describe()
import weightwatcher as ww
watcher = ww.WeightWatcher(model=your_llm)
details = watcher.descrobe()
The watcher produces the details, a dataframe with various layer information:

Notice that in an LLM, each invidudual layer is a DENSE layer–even the ones making up the transformer layers. In order to only select the MLP layers, we need to identify them (by name, and then number)
Selecting Specific Layers
The LASER paper recommends applying (what we call) SVDSmoothing to specific layers of an LLM, such as the MLP/DENSE layers towards the end of the model (closer to the labels)
We can select specific layers by id (number), by type (i.e DENSE), or by name. To select the MLP layers, lets just get list of TinyLLaMA layers that have the term ‘mlp’ in them
import pandas as pd
# Assuming 'details' is your DataFrame
D = details[details['name'].astype(str).str.contains('mlp')]
# Now, extract 'layer_id' column as a list of ids
mlp_layer_ids = list(D['layer_id'].to_numpy())
Now that we have the layers listed out, we need to select the method for choosing our low rank (TruncatedSVD) approximation. We then specify layer_ids=…
smoothed_model = watcher.SVDSmoothing(layers=mlp_layer_ids, ...)
Selecting a Low-Rank Approximation
The weightwatcher tool offers several different automated methods for selecting the SVD subspace for the low rank approximation. This subspace can be selected as the eigencomponents associated with the method=… (and the optional percent=…) option(s):
smoothed_model = watcher.SVDSmoothing(method='svd', percent=0.2, ...)
where the method option can be
method = ‘detX’ (default) | ‘rmt’ | ‘svd’ | ‘alpha_min’
The default method , ‘detX, select the top eigenvalues satisfying the detX condition, i.e. a volume perserving transformation.
- method=’detX ‘: default
This is approximately the same as using method=’svd’ , with ‘percent’=0.8 (80% of the rank is retained)
- method=’svd ‘,percent=P: the top P percent of the largest eigenvalues
Other options are:
- method=’alpha_min’: the eigenvalues in the fitted Power Law tail
- method = ‘rmt’: the large spikes, or eigenvalues larger than the MP (Marhcenko Pastur) bulk region predicted by RMT (Random Matrix Theory)–currently broken, needs fixed
and in the future, weightwatcher will also offer method=’entropy’, which will select the SVD subspace based on the entropy of the eigenvectors.
For now, lets keep it simple and pretty conservative and use the default (which picks the top eigencomponents associated with ~60-80% largest eigenvalyes of each individual layer weight matrix)
Generating the Smoothed Model
watcher = ww.WeightWatcher(model=tinyLLaMA)
smoothed_model = watcher.SVDSmoothing(layers=mlp_layer_ids)
Testing the Smoothed Model
Now we save the smoother model to the folder we created aove
torch.save(smoothed_model, smoothed_model_filename)
To test the models, we will generate some fake text from a prompt and compare. Just a sanity check.
We meed a tokenizer; will share the tokenizer between models
from transformers import AutoTokenizer, pipeline
import torch
# Initialize the tokenizer from the local directory
tokenizer = AutoNow, Tokenizer.from_pretrained(tinyLLaMA_folder)
We then specify the model folder to create a text generation pipeline. For the orginal TinyLlama, we use
# Manually set the device you want to use (e.g., 'cuda' for GPU or 'cpu' for CPU)
# If you want to automatically use GPU if available, you can use torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Initialize the pipeline and specify the local model directory
text_generation_pipeline = pipeline(
"text-generation",
model=tinyLLaMA_folder,
tokenizer=tokenizer,
framework="pt", # Specify the framework 'pt' for PyTorch
)
and for the smoothed model, we use
smoothed_generation_pipeline = pipeline(
"text-generation",
model=smoothed_model_folder,
tokenizer=tokenizer,
device=device, # Use the manually specified device
framework="pt", # Specify the framework 'pt' for PyTorch
)
Now we can generate some text and compare the results of the original and the smoothed model. Lets just do a sanity check:
# Use the pipeline for text generation (as an example)
generated_text = text_generation_pipeline("Who was the first US president ?", max_length=20)
print(generated_text)
The original response is
“Who was the first US president ?\nThe first US president was George Washington.\n…”
generated_text = smoothed_generation_pipeline("Who was the first US president ?", max_length=20)
print(generated_text)a
The smoother result is:
“Who was the first US president ?\nThe first US president was George Washington.\n…”
and matches the above correct result (above)
Let me encourage you to try this, with different settings for SVDSmoothing, and decide for yourself what is a good result.
Why does SVDSmothing Work ?
I have discussed this in great detail in my invited talk at NeurIPS2023 in our Workshop on Heavy Tails in ML. To view the all the workshop vidoes, go here.
Breifly, the weightwatcher theory postulates that for any very well-trained DNN, the correlations in the layer concentrate into the eigencomponents associated with the tail of the layer ESD. And that this tends to happen when the weightwatcher layer quality metric alpha is 2.0, and, simultaneously, when the detX / volume preserving condition holds. We call this subspace the Effective Correlation Space (ECS).
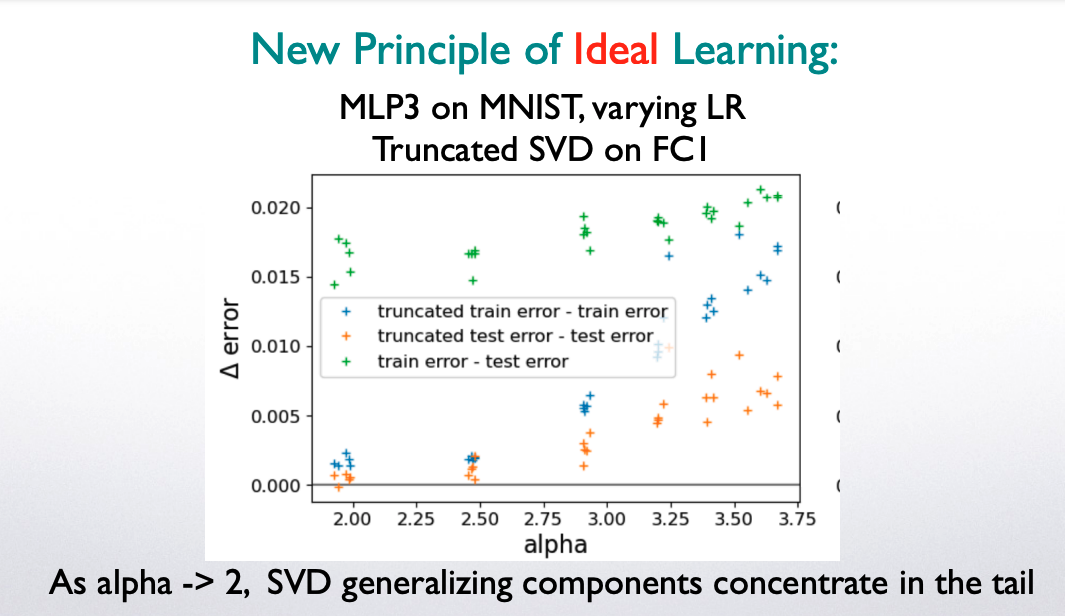
For example, if we train a small, 3-layer MLP on the MNIST data set, we can see that when the FC1 layer alpha -> 2, then we can then replace the FC1 weight matrix W with its ‘Smoothed’ form, and, subsequently, reproduce the original test error (orange) exactly!
Moreover, we can not reproduce the training error (blue); the ‘Smoothed’ training error is always a smaller larger than the original training error, but larger than zero.
This is very easy to reproduce and I will share some Jupyter Notebooks to anyone who wants to try this.
This experiment shows that the parts of W that contribute to the generalization ability into the Effective Correlation Space (ECS) defined by the tail of the ESD.
When running SVDSmoothing, if you use the method=detX default option, weightwatcher will attempt to define the ECS automatically for you, but if alpha > 2, the Effective Correlation Space (ECS) will be larger than necessary, just to be safe.
If you run the SVDSmoothing this yourself, please join our Community Discord and share your learnings with us.
The weightwatcher tool has been developed by Calculation Consulting. We provide consulting to companies looking to implement Data Science, Machine Learning, and/or AI solutions. Reach out today to learn how to get started with your own AI project. Email: Info@CalculationConsulting.com
via https://AIupNow.com
Charles H Martin, PhD, Khareem Sudlow



