Marc Olson has been part of the team shaping Elastic Block Store (EBS) for over a decade. In that time, he’s helped to drive the dramatic evolution of EBS from a simple block storage service relying on shared drives to a massive network storage system that delivers over 140 trillion daily operations.
In this post, Marc provides a fascinating insider’s perspective on the journey of EBS. He shares hard-won lessons in areas such as queueing theory, the importance of comprehensive instrumentation, and the value of incrementalism versus radical changes. Most importantly, he emphasizes how constraints can often breed creative solutions. It’s an insightful look at how one of AWS’s foundational services has evolved to meet the needs of our customers (and the pace at which they’re innovating).
–W
Continuous reinvention: A brief history of block storage at AWS
I’ve built system software for most of my career, and before joining AWS it was mostly in the networking and security spaces. When I joined AWS nearly 13 years ago, I entered a new domain—storage—and stepped into a new challenge. Even back then the scale of AWS dwarfed anything I had worked on, but many of the same techniques I had picked up until that point remained applicable—distilling problems down to first principles, and using successive iteration to incrementally solve problems and improve performance.
If you look around at AWS services today, you’ll find a mature set of core building blocks, but it wasn’t always this way. EBS launched on August 20, 2008, nearly two years after EC2 became available in beta, with a simple idea to provide network attached block storage for EC2 instances. We had one or two storage experts, and a few distributed systems folks, and a solid knowledge of computer systems and networks. How hard could it be? In retrospect, if we knew at the time how much we didn’t know, we may not have even started the project!
Since I’ve been at EBS, I’ve had the opportunity to be part of the team that’s evolved EBS from a product built using shared hard disk drives (HDDs), to one that is capable of delivering hundreds of thousands of IOPS (IO operations per second) to a single EC2 instance. It’s remarkable to reflect on this because EBS is capable of delivering more IOPS to a single instance today than it could deliver to an entire Availability Zone (AZ) in the early years on top of HDDs. Even more amazingly, today EBS in aggregate delivers over 140 trillion operations daily across a distributed SSD fleet. But we definitely didn’t do it overnight, or in one big bang, or even perfectly. When I started on the EBS team, I initially worked on the EBS client, which is the piece of software responsible for converting instance IO requests into EBS storage operations. Since then I’ve worked on almost every component of EBS and have been delighted to have had the opportunity to participate so directly in the evolution and growth of EBS.
As a storage system, EBS is a bit unique. It’s unique because our primary workload is system disks for EC2 instances, motivated by the hard disks that used to sit inside physical datacenter servers. A lot of storage services place durability as their primary design goal, and are willing to degrade performance or availability in order to protect bytes. EBS customers care about durability, and we provide the primitives to help them achieve high durability with io2 Block Express volumes and volume snapshots, but they also care a lot about the performance and availability of EBS volumes. EBS is so closely tied as a storage primitive for EC2, that the performance and availability of EBS volumes tends to translate almost directly to the performance and availability of the EC2 experience, and by extension the experience of running applications and services that are built using EC2. The story of EBS is the story of understanding and evolving performance in a very large-scale distributed system that spans layers from guest operating systems at the top, all the way down to custom SSD designs at the bottom. In this post I’d like to tell you about the journey that we’ve taken, including some memorable lessons that may be applicable to your systems. After all, systems performance is a complex and really challenging area, and it’s a complex language across many domains.
Queueing theory, briefly
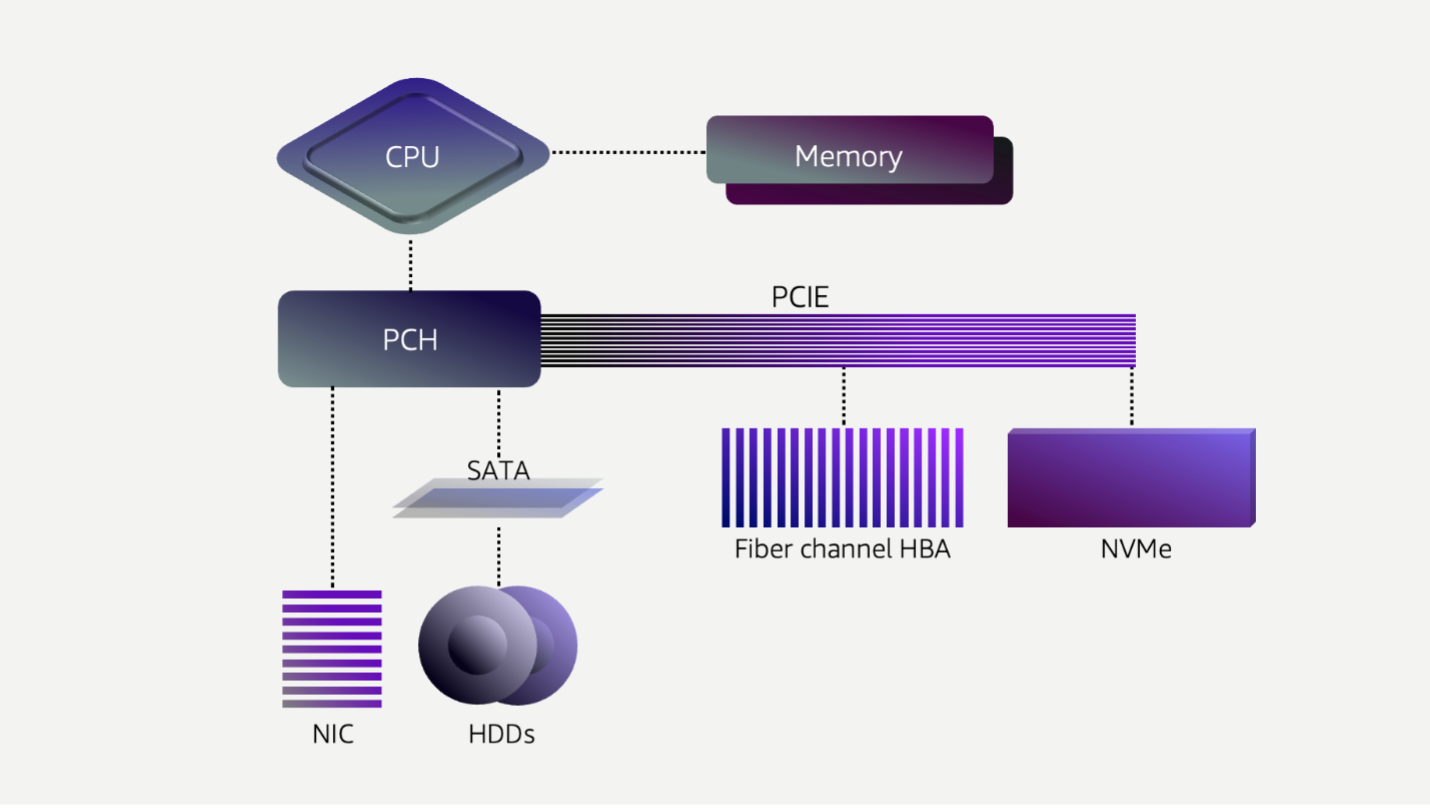
Before we dive too deep, let’s take a step back and look at how computer systems interact with storage. The high-level basics haven’t changed through the years—a storage device is connected to a bus which is connected to the CPU. The CPU queues requests that travel the bus to the device. The storage device either retrieves the data from CPU memory and (eventually) places it onto a durable substrate, or retrieves the data from the durable media, and then transfers it to the CPU’s memory.
You can think of this like a bank. You walk into the bank with a deposit, but first you have to traverse a queue before you can speak with a bank teller who can help you with your transaction. In a perfect world, the number of patrons entering the bank arrive at the exact rate at which their request can be handled, and you never have to stand in a queue. But the real world isn’t perfect. The real world is asynchronous. It’s more likely that a few people enter the bank at the same time. Perhaps they have arrived on the same streetcar or train. When a group of people all walk into the back at the same time, some of them are going to have to wait for the teller to process the transactions ahead of them.
As we think about the time to complete each transaction, and empty the queue, the average time waiting in line (latency) across all customers may look acceptable, but the first person in the queue had the best experience, while the last had a much longer delay. There are a number of things the bank can do to improve the experience for all customers. The bank could add more tellers to process more requests in parallel, it could rearrange the teller workflows so that each transaction takes less time, lowering both the total time and the average time, or it could create different queues for either latency insensitive customers or consolidating transactions that may be faster to keep the queue low. But each of these options comes at an additional cost—hiring more tellers for a peak that may never occur, or adding more real estate to create separate queues. While imperfect, unless you have infinite resources, queues are necessary to absorb peak load.
In network storage systems, we have several queues in the stack, including those between the operating system kernel and the storage adapter, the host storage adapter to the storage fabric, the target storage adapter, and the storage media. In legacy network storage systems, there may be different vendors for each component, and different ways that they think about servicing the queue. You may be using a dedicated, lossless network fabric like fiber channel, or using iSCSI or NFS over TCP, either with the operating system network stack, or a custom driver. In either case, tuning the storage network often takes specialized knowledge, separate from tuning the application or the storage media.
When we first built EBS in 2008, the storage market was largely HDDs, and the latency of our service was dominated by the latency of this storage media. Last year, Andy Warfield went in-depth about the fascinating mechanical engineering behind HDDs. As an engineer, I still marvel at everything that goes into a hard drive, but at the end of the day they are mechanical devices and physics limits their performance. There’s a stack of platters that are spinning at high velocity. These platters have tracks that contain the data. Relative to the size of a track (<100 nanometers), there’s a large arm that swings back and forth to find the right track to read or write your data. Because of the physics involved, the IOPS performance of a hard drive has remained relatively constant for the last few decades at approximately 120-150 operations per second, or 6-8 ms average IO latency. One of the biggest challenges with HDDs is that tail latencies can easily drift into the hundreds of milliseconds with the impact of queueing and command reordering in the drive.
We didn’t have to worry much about the network getting in the way since end-to-end EBS latency was dominated by HDDs and measured in the 10s of milliseconds. Even our early data center networks were beefy enough to handle our user’s latency and throughput expectations. The addition of 10s of microseconds on the network was a small fraction of overall latency.
Compounding this latency, hard drive performance is also variable depending on the other transactions in the queue. Smaller requests that are scattered randomly on the media take longer to find and access than several large requests that are all next to each other. This random performance led to wildly inconsistent behavior. Early on, we knew that we needed to spread customers across many disks to achieve reasonable performance. This had a benefit, it dropped the peak outlier latency for the hottest workloads, but unfortunately it spread the inconsistent behavior out so that it impacted many customers.
When one workload impacts another, we call this a “noisy neighbor.” Noisy neighbors turned out to be a critical problem for the business. As AWS evolved, we learned that we had to focus ruthlessly on a high-quality customer experience, and that inevitably meant that we needed to achieve strong performance isolation to avoid noisy neighbors causing interference with other customer workloads.
At the scale of AWS, we often run into challenges that are hard and complex due to the scale and breadth of our systems, and our focus on maintaining the customer experience. Surprisingly, the fixes are often quite simple once you deeply understand the system, and have enormous impact due to the scaling factors at play. We were able to make some improvements by changing scheduling algorithms to the drives and balancing customer workloads across even more spindles. But all of this only resulted in small incremental gains. We weren’t really hitting the breakthrough that truly eliminated noisy neighbors. Customer workloads were too unpredictable to achieve the consistency we knew they needed. We needed to explore something completely different.
Set long term goals, but don’t be afraid to improve incrementally
Around the time I started at AWS in 2011, solid state disks (SSDs) became more mainstream, and were available in sizes that started to make them attractive to us. In an SSD, there is no physical arm to move to retrieve data—random requests are nearly as fast as sequential requests—and there are multiple channels between the controller and NAND chips to get to the data. If we revisit the bank example from earlier, replacing an HDD with an SSD is like building a bank the size of a football stadium and staffing it with superhumans that can complete transactions orders of magnitude faster. A year later we started using SSDs, and haven’t looked back.
We started with a small, but meaningful milestone: we built a new storage server type built on SSDs, and a new EBS volume type called Provisioned IOPS. Launching a new volume type is no small task, and it also limits the workloads that can take advantage of it. For EBS, there was an immediate improvement, but it wasn’t everything we expected.
We thought that just dropping SSDs in to replace HDDs would solve almost all of our problems, and it certainly did address the problems that came from the mechanics of hard drives. But what surprised us was that the system didn’t improve nearly as much as we had hoped and noisy neighbors weren’t automatically fixed. We had to turn our attention to the rest of our stack—the network and our software—that the improved storage media suddenly put a spotlight on.
Even though we needed to make these changes, we went ahead and launched in August 2012 with a maximum of 1,000 IOPS, 10x better than existing EBS standard volumes, and ~2-3 ms average latency, a 5-10x improvement with significantly improved outlier control. Our customers were excited for an EBS volume that they could begin to build their mission critical applications on, but we still weren’t satisfied and we realized that the performance engineering work in our system was really just beginning. But to do that, we had to measure our system.
If you can’t measure it, you can’t manage it
At this point in EBS’s history (2012), we only had rudimentary telemetry. To know what to fix, we had to know what was broken, and then prioritize those fixes based on effort and rewards. Our first step was to build a method to instrument every IO at multiple points in every subsystem—in our client initiator, network stack, storage durability engine, and in our operating system. In addition to monitoring customer workloads, we also built a set of canary tests that run continuously and allowed us to monitor impact of changes—both positive and negative—under well-known workloads.
With our new telemetry we identified a few major areas for initial investment. We knew we needed to reduce the number of queues in the entire system. Additionally, the Xen hypervisor had served us well in EC2, but as a general-purpose hypervisor, it had different design goals and many more features than we needed for EC2. We suspected that with some investment we could reduce complexity of the IO path in the hypervisor, leading to improved performance. Moreover, we needed to optimize the network software, and in our core durability engine we needed to do a lot of work organizationally and in code, including on-disk data layout, cache line optimization, and fully embracing an asynchronous programming model.
A really consistent lesson at AWS is that system performance issues almost universally span a lot of layers in our hardware and software stack, but even great engineers tend to have jobs that focus their attention on specific narrower areas. While the much celebrated ideal of a “full stack engineer” is valuable, in deep and complex systems it’s often even more valuable to create cohorts of experts who can collaborate and get really creative across the entire stack and all their individual areas of depth.
By this point, we already had separate teams for the storage server and for the client, so we were able to focus on these two areas in parallel. We also enlisted the help of the EC2 hypervisor engineers and formed a cross-AWS network performance cohort. We started to build a blueprint of both short-term, tactical fixes and longer-term architectural changes.
Divide and conquer
When I was an undergraduate student, while I loved most of my classes, there were a couple that I had a love-hate relationship with. “Algorithms” was taught at a graduate level at my university for both undergraduates and graduates. I found the coursework intense, but I eventually fell in love with the topic, and Introduction to Algorithms, commonly referred to as CLR, is one of the few textbooks I retained, and still occasionally reference. What I didn’t realize until I joined Amazon, and seems obvious in hindsight, is that you can design an organization much the same way you can design a software system. Different algorithms have different benefits and tradeoffs in how your organization functions. Where practical, Amazon chooses a divide and conquer approach, and keeps teams small and focused on a self-contained component with well-defined APIs.
This works well when applied to components of a retail website and control plane systems, but it’s less intuitive in how you could build a high-performance data plane this way, and at the same time improve performance. In the EBS storage server, we reorganized our monolithic development team into small teams focused on specific areas, such as data replication, durability, and snapshot hydration. Each team focused on their unique challenges, dividing the performance optimization into smaller sized bites. These teams are able to iterate and commit their changes independently—made possible by rigorous testing that we’ve built up over time. It was important for us to make continual progress for our customers, so we started with a blueprint for where we wanted to go, and then began the work of separating out components while deploying incremental changes.
The best part of incremental delivery is that you can make a change and observe its impact before making the next change. If something doesn’t work like you expected, then it’s easy to unwind it and go in a different direction. In our case, the blueprint that we laid out in 2013 ended up looking nothing like what EBS looks like today, but it gave us a direction to start moving toward. For example, back then we never would have imagined that Amazon would one day build its own SSDs, with a technology stack that could be tailored specifically to the needs of EBS.
Always question your assumptions!
Challenging our assumptions led to improvements in every single part of the stack.
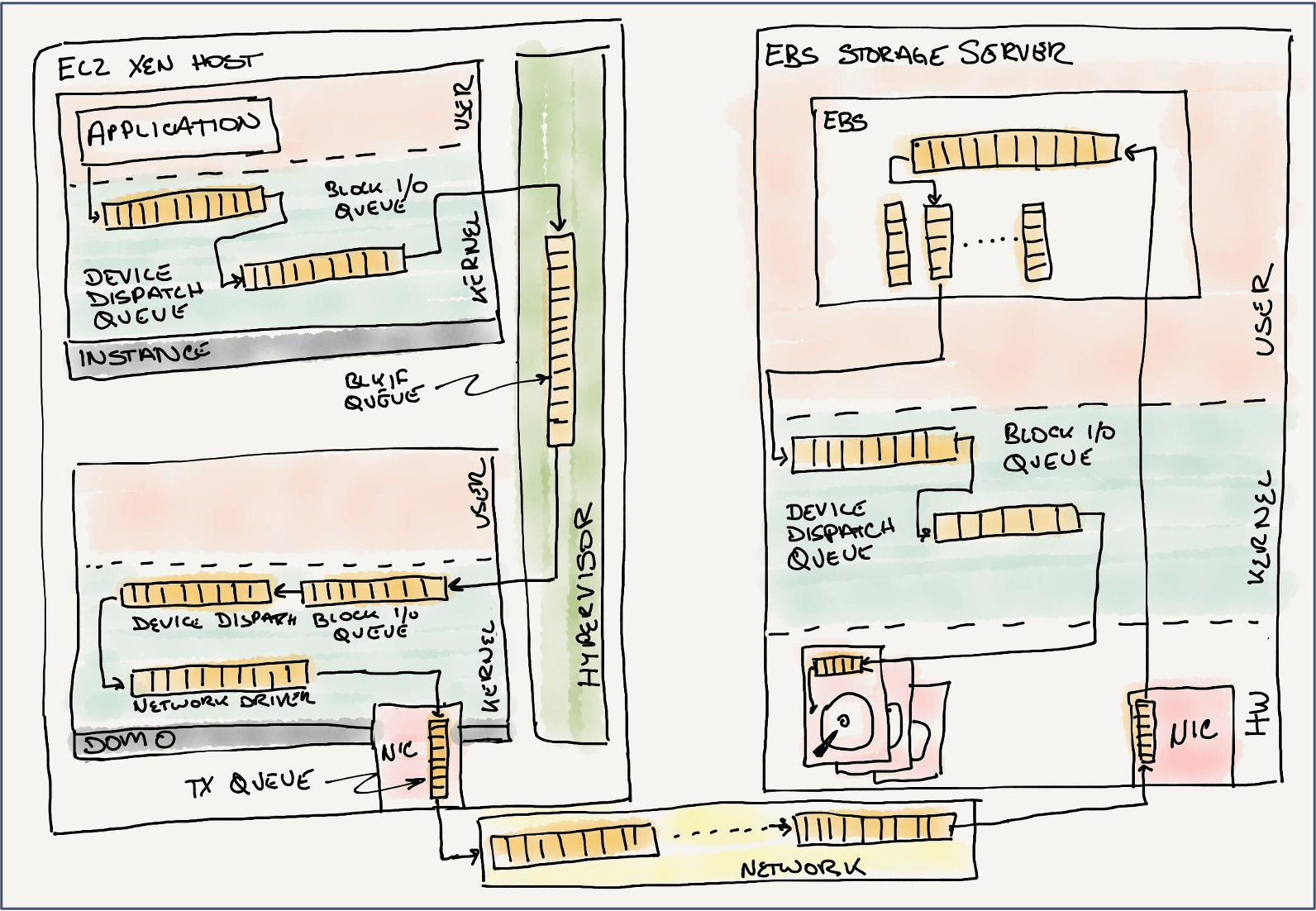
We started with software virtualization. Until late 2017 all EC2 instances ran on the Xen hypervisor. With devices in Xen, there is a ring queue setup that allows guest instances, or domains, to share information with a privileged driver domain (dom0) for the purposes of IO and other emulated devices. The EBS client ran in dom0 as a kernel block device. If we follow an IO request from the instance, just to get off of the EC2 host there are many queues: the instance block device queue, the Xen ring, the dom0 kernel block device queue, and the EBS client network queue. In most systems, performance issues are compounding, and it’s helpful to focus on components in isolation.
One of the first things that we did was to write several “loopback” devices so that we could isolate each queue to gauge the impact of the Xen ring, the dom0 block device stack, and the network. We were almost immediately surprised that with almost no latency in the dom0 device driver, when multiple instances tried to drive IO, they would interact with each other enough that the goodput of the entire system would slow down. We had found another noisy neighbor! Embarrassingly, we had launched EC2 with the Xen defaults for the number of block device queues and queue entries, which were set many years prior based on the limited storage hardware that was available to the Cambridge lab building Xen. This was very unexpected, especially when we realized that it limited us to only 64 IO outstanding requests for an entire host, not per device—certainly not enough for our most demanding workloads.
We fixed the main issues with software virtualization, but even that wasn’t enough. In 2013, we were well into the development of our first Nitro offload card dedicated to networking. With this first card, we moved the processing of VPC, our software defined network, from the Xen dom0 kernel, into a dedicated hardware pipeline. By isolating the packet processing data plane from the hypervisor, we no longer needed to steal CPU cycles from customer instances to drive network traffic. Instead, we leveraged Xen’s ability to pass a virtual PCI device directly to the instance.
This was a fantastic win for latency and efficiency, so we decided to do the same thing for EBS storage. By moving more processing to hardware, we removed several operating system queues in the hypervisor, even if we weren’t ready to pass the device directly to the instance just yet. Even without passthrough, by offloading more of the interrupt driven work, the hypervisor spent less time servicing the requests—the hardware itself had dedicated interrupt processing functions. This second Nitro card also had hardware capability to handle EBS encrypted volumes with no impact to EBS volume performance. Leveraging our hardware for encryption also meant that the encryption key material is kept separate from the hypervisor, which further protects customer data.
Moving EBS to Nitro was a huge win, but it almost immediately shifted the overhead to the network itself. Here the problem seemed simple on the surface. We just needed to tune our wire protocol with the latest and greatest data center TCP tuning parameters, while choosing the best congestion control algorithm. There were a few shifts that were working against us: AWS was experimenting with different data center cabling topology, and our AZs, once a single data center, were growing beyond those boundaries. Our tuning would be beneficial, as in the example above, where adding a small amount of random latency to requests to storage servers counter-intuitively reduced the average latency and the outliers due to the smoothing effect it has on the network. These changes were ultimately short lived as we continuously increased the performance and scale of our system, and we had to continually measure and monitor to make sure we didn’t regress.
Knowing that we would need something better than TCP, in 2014 we started laying the foundation for Scalable Relatable Diagram (SRD) with “A Cloud-Optimized Transport Protocol for Elastic and Scalable HPC”. Early on we set a few requirements, including a protocol that could improve our ability to recover and route around failures, and we wanted something that could be easily offloaded into hardware. As we were investigating, we made two key observations: 1/ we didn’t need to design for the general internet, but we could focus specifically on our data center network designs, and 2/ in storage, the execution of IO requests that are in flight could be reordered. We didn’t need to pay the penalty of TCP’s strict in-order delivery guarantees, but could instead send different requests down different network paths, and execute them upon arrival. Any barriers could be handled at the client before they were sent on the network. What we ended up with is a protocol that’s useful not just for storage, but for networking, too. When used in Elastic Network Adapter (ENA) Express, SRD improves the performance of your TCP stacks in your guest. SRD can drive the network at higher utilization by taking advantage of multiple network paths and reducing the overflow and queues in the intermediate network devices.
Performance improvements are never about a single focus. It’s a discipline of continuously challenging your assumptions, measuring and understanding, and shifting focus to the most meaningful opportunities.
Constraints breed innovation
We weren’t satisfied that only a relatively small number of volumes and customers had better performance. We wanted to bring the benefits of SSDs to everyone. This is an area where scale makes things difficult. We had a large fleet of thousands of storage servers running millions of non-provisioned IOPS customer volumes. Some of those same volumes still exist today. It would be an expensive proposition to throw away all of that hardware and replace it.
There was empty space in the chassis, but the only location that didn’t cause disruption in the cooling airflow was between the motherboard and the fans. The nice thing about SSDs is that they are typically small and light, but we couldn’t have them flopping around loose in the chassis. After some trial and error—and help from our material scientists—we found heat resistant, industrial strength hook and loop fastening tape, which also let us service these SSDs for the remaining life of the servers.

Armed with this knowledge, and a lot of human effort, over the course of a few months in 2013, EBS was able to put a single SSD into each and every one of those thousands of servers. We made a small change to our software that staged new writes onto that SSD, allowing us to return completion back to your application, and then flushed the writes to the slower hard disk asynchronously. And we did this with no disruption to customers—we were converting a propeller aircraft to a jet while it was in flight. The thing that made this possible is that we designed our system from the start with non-disruptive maintenance events in mind. We could retarget EBS volumes to new storage servers, and update software or rebuild the empty servers as needed.
This ability to migrate customer volumes to new storage servers has come in handy several times throughout EBS’s history as we’ve identified new, more efficient data structures for our on-disk format, or brought in new hardware to replace the old hardware. There are volumes still active from the first few months of EBS’s launch in 2008. These volumes have likely been on hundreds of different servers and multiple generations of hardware as we’ve updated and rebuilt our fleet, all without impacting the workloads on those volumes.
Reflecting on scaling performance
There’s one more journey over this time that I’d like to share, and that’s a personal one. Most of my career prior to Amazon had been in either early startup or similarly small company cultures. I had built managed services, and even distributed systems out of necessity, but I had never worked on anything close to the scale of EBS, even the EBS of 2011, both in technology and organization size. I was used to solving problems by myself, or maybe with one or two other equally motivated engineers.
I really enjoy going super deep into problems and attacking them until they’re complete, but there was a pivotal moment when a colleague that I trusted pointed out that I was becoming a performance bottleneck for our organization. As an engineer who had grown to be an expert in the system, but also who cared really, really deeply about all aspects of EBS, I found myself on every escalation and also wanting to review every commit and every proposed design change. If we were going to be successful, then I had to learn how to scale myself–I wasn’t going to solve this with just ownership and bias for action.
This led to even more experimentation, but not in the code. I knew I was working with other smart folks, but I also needed to take a step back and think about how to make them effective. One of my favorite tools to come out of this was peer debugging. I remember a session with a handful of engineers in one of our lounge rooms, with code and a few terminals projected on a wall. One of the engineers exclaimed, “Uhhhh, there’s no way that’s right!” and we had found something that had been nagging us for a while. We had overlooked where and how we were locking updates to critical data structures. Our design didn’t usually cause issues, but occasionally we would see slow responses to requests, and fixing this removed one source of jitter. We don’t always use this technique, but the neat thing is that we are able to combine our shared systems knowledge when things get really tricky.
Through all of this, I realized that empowering people, giving them the ability to safely experiment, can often lead to results that are even better than what was expected. I’ve spent a large portion of my career since then focusing on ways to remove roadblocks, but leave the guardrails in place, pushing engineers out of their comfort zone. There’s a bit of psychology to engineering leadership that I hadn’t appreciated. I never expected that one of the most rewarding parts of my career would be encouraging and nurturing others, watching them own and solve problems, and most importantly celebrating the wins with them!
Conclusion
Reflecting back on where we started, we knew we could do better, but we weren’t sure how much better. We chose to approach the problem, not as a big monolithic change, but as a series of incremental improvements over time. This allowed us to deliver customer value sooner, and course correct as we learned more about changing customer workloads. We’ve improved the shape of the EBS latency experience from one averaging more than 10 ms per IO operation to consistent sub-millisecond IO operations with our highest performing io2 Block Express volumes. We accomplished all this without taking the service offline to deliver a new architecture.
We know we’re not done. Our customers will always want more, and that challenge is what keeps us motivated to innovate and iterate.
Related posts
via https://www.aiupnow.com
werner@allthingsdistributed.com (Dr. Werner Vogels), Khareem Sudlow

